| Exercise 7 | Voting Analysis Project |
| Data | Election Mapping (GML) Election Statistics (Microsoft Excel) |
| Overall Goal | Map statistics of voting patterns |
| Demonstrates | Data Transformation |
| Start Workspace | C:\FMEData2018\Workspaces\DesktopBasic\Transformation-Ex7-Begin.fmw |
| End Workspace | C:\FMEData2018\Workspaces\DesktopBasic\Transformation-Ex7-Complete.fmw C:\FMEData2018\Workspaces\DesktopBasic\Transformation-Ex7-Complete-Advanced.fmw |
In a break from grounds maintenance projects, the municipal Elections Officer has heard about your skills and asked for help identifying voting divisions that had a low turnout at the last election, or divisions where voters had difficulties understanding the process.
He asks for your help, and you suggest the results should be presented in Google Earth so that staff can view them without having to use a full GIS system.
1) Inspect Data
Start the FME Data Inspector and open the two datasets we will be using:
| Reader Format | GML (Geography Markup Language) |
| Reader Dataset | C:\FMEData2018\Data\Elections\ElectionVoting.gml |
| Reader Format | Microsoft Excel |
| Reader Dataset | C:\FMEData2018\Data\Elections\ElectionResults.xls |
Notice that both datasets have a Division attribute by which to identify each voting division (area). The Excel data is non-spatial but has a set of other voting attributes:
- Voters: Number of registered voters
- Votes: Number of voters who voted
- Blanks: Number of voters who left a blank or spoiled vote
- OverVotes: Number of voters who voted for too many candidates
- UnderVotes: Number of votes not cast
The OverVotes and UnderVotes attributes are an indicator of how well the voting process was understood. Each voter gets to vote for up to 10 candidates (out of 30).
OverVotes are those voters who voted for more than ten candidates. UnderVotes are the number of votes that could have been cast, but were not; for example, the voter only voted for four candidates instead of ten, giving six undervotes.
2) Start Workbench
Start Workbench and open the starting workspace. It already has readers and writers added to handle the data; all we need to do is carry out the transformation:
3) Add FeatureJoiner
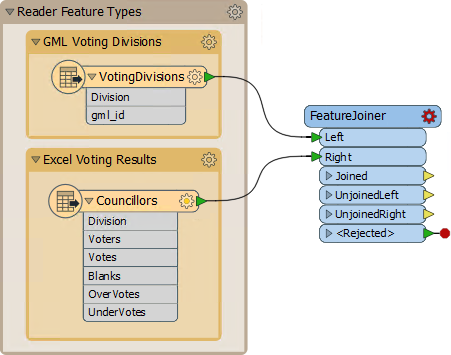
The first task is to join the statistical election data onto the actual features. We'll use a FeatureJoiner transformer to do this. A FeatureJoiner is a way to join or merge features. In this case, we are merging election result records onto election boundary features.
Add a FeatureJoiner transformer. Connect the VotingDivisions data to the Left port, and the Councillors (result) data to the Right port:
| NEW |
| The FeatureJoiner is a new transformer for FME2018, designed to eventually replace the FeatureMerger. |
4) Set Parameters
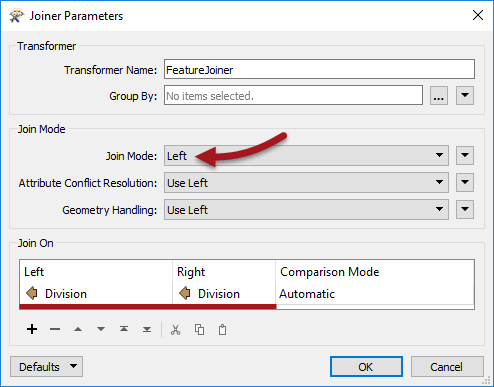
View the FeatureJoiner parameters. Because we want all of the voting division features we will do a Left join; therefore set the Join Mode to Left.
For both the Left and Right join fields, click in the field and choose the Division attribute from the drop-down list. This attribute is the common key by which we join our data:
5) Add Inspector Transformer
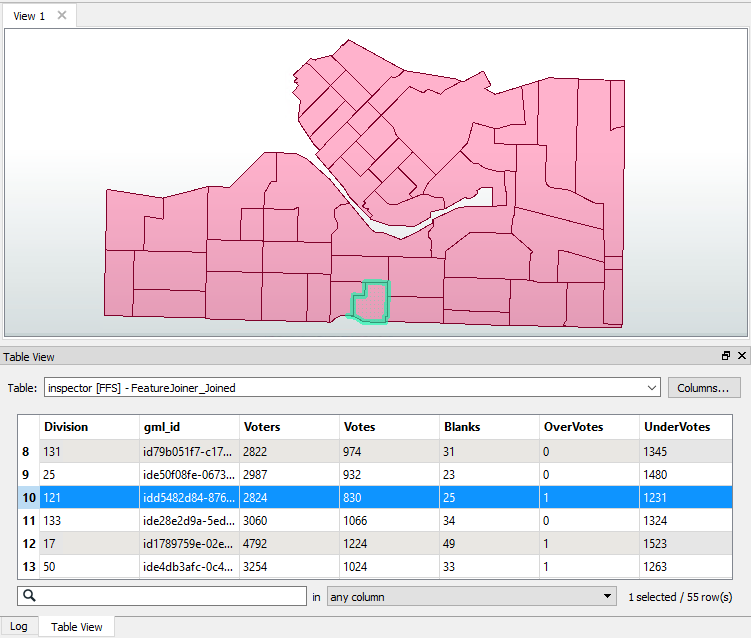
Add an Inspector transformer after the FeatureJoiner:Joined output port. Run the workspace, ignoring any warning or log message that reports Unexpected Input.
Examine the data in the FME Data Inspector to ensure all division polygons now include a set of attribute data copied from the Excel spreadsheet:
6) Add ExpressionEvaluator
Now that we have the numbers we need, we can start to calculate some statistics. To do this, we'll use an ExpressionEvaluator transformer first to calculate the voter turnout percentage for each division.
Place an ExpressionEvaluator transformer after the FeatureJoiner - connect it to the FeatureJoiner:Joined output port. View the transformer's parameters. Set the New Attribute to Turnout (to match what we have on the destination schema):
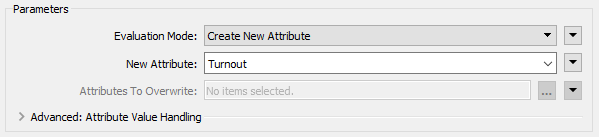
In the expression window, set the expression to:
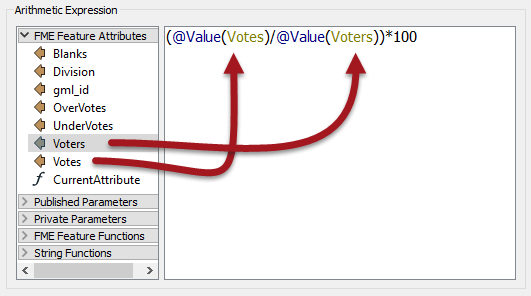
(@Value(Votes)/@Value(Voters))*100
You don't need to type this in - the @Value(Votes) and @Value(Voters) part can be obtained by double-clicking that attribute in the list to the left.
If you wish, you can reconnect an Inspector and re-run the translation, to see the result.
7) Add ExpressionEvaluator
Using a similar technique, add a second ExpressionEvaluator to calculate the number of UnderVotes per voter and put it in an attribute that matches the output schema (for example UnderVoting). The expression will be something like:
@Value(UnderVotes)/@Value(Voters)
NB: This isn't a percentage, like the previous calculation.
Feel free to add a bookmark around the two ExpressionEvaluator transformers.
8) Add AttributeRounder
It's a bit excessive to calculate our statistics to 13 decimal places or more. We should truncate these numbers a bit. To do this place an AttributeRounder transformer after the second ExpressionEvaluator.
For the parameters, under Attributes to Round select the newly created Turnout and UnderVoting attributes. Set the number of decimal places to 2:
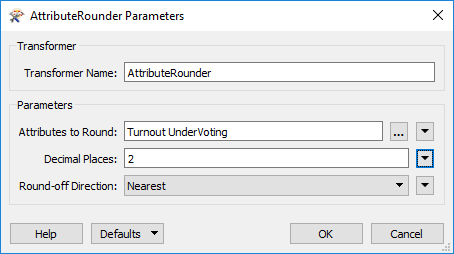
Again, run the workspace to check the results if you wish.
9) Add Annotation
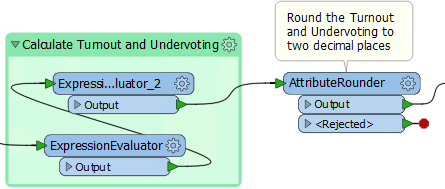
It doesn't make sense to add a bookmark to the AttributeRounder by itself, so instead right-click the transformer and choose the option to Attach Annotation.
Doing so will add a label to the transformer. Edit the content to say something like "Round the Turnout and Undervoting to two decimal places":
10) Connect Schema
For the final step let's connect the AttributeRounder to the output schema. Simply make connections from the AttributeRounder to both writer feature types:
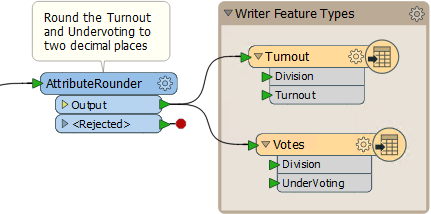
Run the workspace and examine the output in Google Earth to prove it has the correct attributes and is in the correct location.
| TIP |
So this is obviously a form of parallel streams of data, but left until the last step. An alternative layout would be to split the data after the FeatureJoiner, like so:
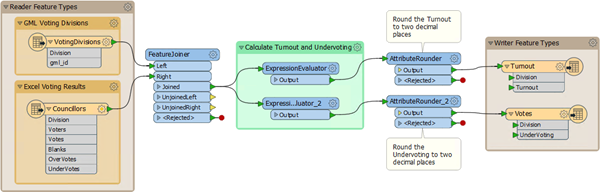
There's no difference in the output so the only consideration is which is easier to create and which will perform better. The main method used should win on both counts. |
| Advanced Exercise |
|
The project is done, but the output is very plain. It would be much better to improve the look of the results and there are several ways to do this with KML.
We could simply color the voting divisions differently according to their turnout/overvotes, but a more impressive method is to use three-dimensional blocks. Follow the steps below to create three-dimensional shapes in the output KML dataset... |
10) Add ExpressionEvaluator
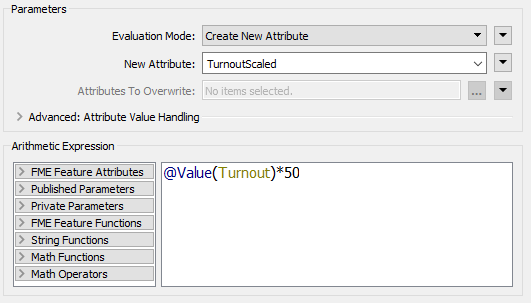
The height of each block should be proportional to the turnout for that division. However, for differences to be visible, the vertical scale will need some exaggeration.
Place an ExpressionEvaluator between the AttributeRounder and the Turnout feature type. Set the parameters to multiply the Turnout attribute by a value of 50. Put it into a new attribute called TurnoutScaled.
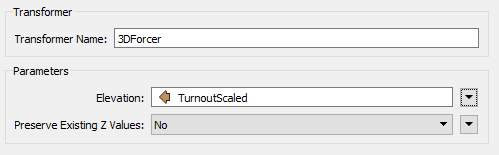
11) Add 3DForcer
Add a 3DForcer transformer after the new ExpressionEvaluator. This will elevate the feature to the required height. In the parameters dialog set the elevation to Attribute Value > TurnoutScaled.
12) Add KMLPropertySetter
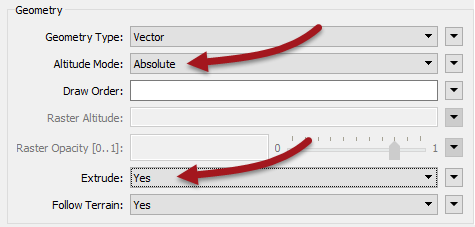
Add a KMLPropertySetter transformer after the 3DForcer. This transformer will allow us to set up the 3D blocks in the output. Set the geometry parameters as follows:
- Altitude Mode: Absolute
- Extrude: Yes
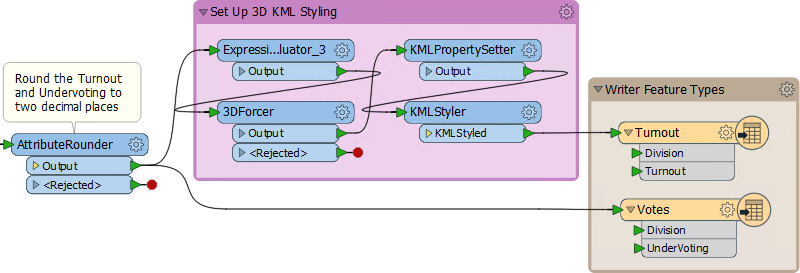
13) Add KMLStyler
Finally, add a KMLStyler transformer. The workspace will now look like this:
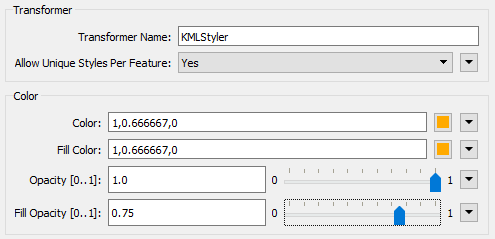
Check the parameters. Select a color and fill color for the features. Increase the fill opacity to around 0.75.
Save and run the workspace. In Google Earth the output should now look like this:
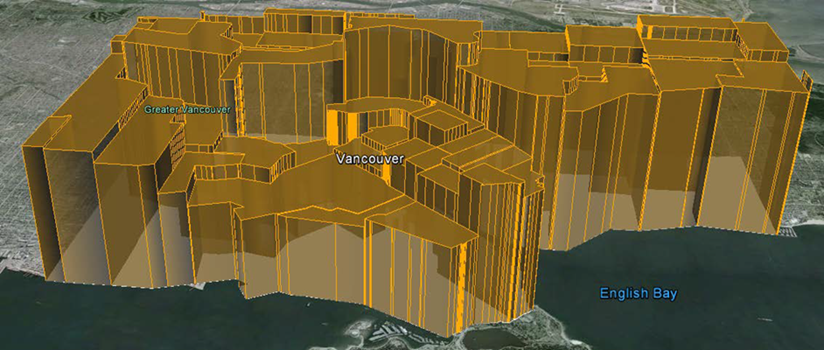
These 3D blocks will show users where the voter turnout is high/low in the city.
If you wish, repeat these steps to give a 3D representation to the UnderVoting statistics.
| CONGRATULATIONS |
By completing this exercise you proved you know how to:
|