Planning for Disaster Recovery
Disaster recovery is primarily concerned with recovering FME Server operations and data in the event of a major failure of a data center. The time frame for disaster recovery is typically longer than fault-tolerant recovery. Disaster recovery may range from minutes, hours, or even days, while fault-tolerant recovery is typically expected in seconds or minutes, and seamless to the end user.
Disaster recovery can be incorporated into any of the fault-tolerant architectures. Alternatively, if you are primarily concerned with disaster recovery, and less concerned - or even not at all concerned - about the fast recovery provided by fault tolerance environment, you may want to implement a different architecture.
The general concept of disaster recovery is that if one data center fails, the second data center takes over, and the FME Server Core located there becomes the active core. Often this type of recovery involves redirecting network traffic to a new server address in the new data center.
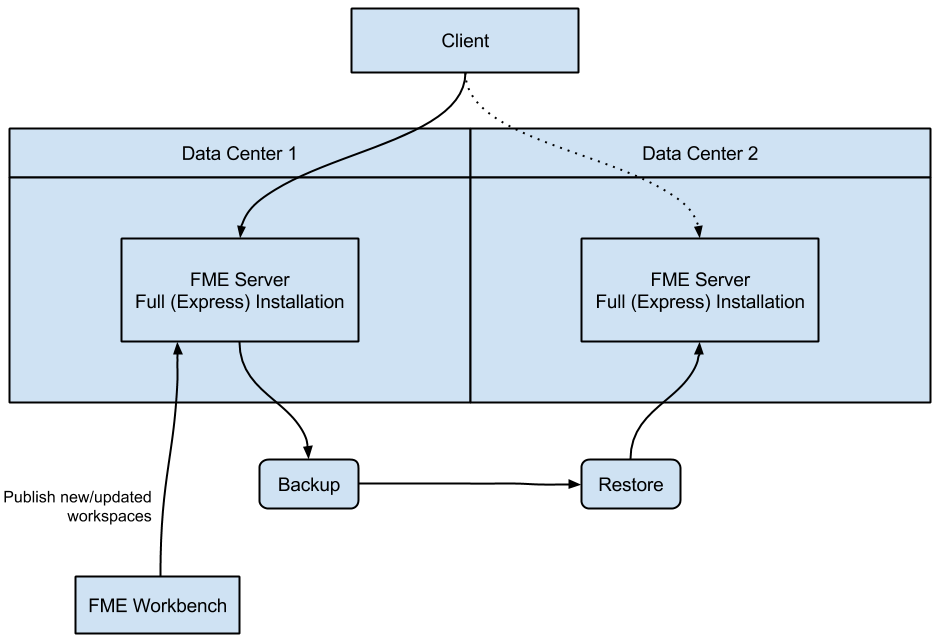
This example of disaster recovery is an adaptation of an Active-Active architecture, but without the third-party load balancer between systems. Instead, FME Server clients must be manually redirected to the Core host server of the second data center in the event of a disaster. Each data center houses full (“Express”) installations of FME Server, essentially configured to provide similar functionality. To ensure synchronicity of the FME Server system data between data centers, Backup & Restore operations are performed regularly. (Otherwise, workspaces must be published twice - to the FME Server Core hosts on each data center).
Keep in mind that when planning for disaster recovery, all clients of FME Server, including web browsers, the FME Server Console, and the FME Server REST API, must connect to the active FME Server Core host.