 Share this Page
Share this PageCS525 - GPU Programming
This section contains the projects I worked on for the GPU Programming class, Spring 2010.
Project 1 - Kodachrome
 The objective for this project was to process a stream of images captured from the webcam, and apply a set of vertex, fragment and geometry shaders to
achieve different visual effects. The shaders had to be written using the OpenGL Shading Language (GLSL). My application made use of the OpenCV library
for the webcam capture part. OpenCV has also been used to integrate face recognition support into one of the shaders.
The objective for this project was to process a stream of images captured from the webcam, and apply a set of vertex, fragment and geometry shaders to
achieve different visual effects. The shaders had to be written using the OpenGL Shading Language (GLSL). My application made use of the OpenCV library
for the webcam capture part. OpenCV has also been used to integrate face recognition support into one of the shaders.
Project 2 - Taste of Chicago
 This project involved the use of a GPU for general purpose computation: the project objective was to recreate a zombie attack in downtown
chicago, implementing an agent-based simulation using the CUDA toolkit.
This project involved the use of a GPU for general purpose computation: the project objective was to recreate a zombie attack in downtown
chicago, implementing an agent-based simulation using the CUDA toolkit.
Paper presentation - FCUDA Enabling Efficient Compilation of CUDA Kernels onto FPGAs
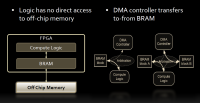 Abstract: As growing power dissipation and thermal effects disrupted the rising clock frequency trend and threatened to annul Moore’s law, the computing industry has switched its route
to higher performance through parallel processing. The rise of multi-core systems in all domains of computing has opened the
door to heterogeneous multi-processors, where processors of different compute characteristics can be combined to effectively boost the performance per watt of different application kernels.
GPUs and FPGAs are becoming very popular in PC-based heterogeneous systems for speeding up compute intensive kernels of scientific, imaging and simulation applications. GPUs can
execute hundreds of concurrent threads, while FPGAs provide customized concurrency for highly parallel kernels. However, exploiting the parallelism available in these applications is often
not a push-button task. Often the programmer has to expose the application’s fine and coarse grained parallelism by using special APIs. CUDA is such a parallel-computing API that is driven by
the GPGPU industry and is gaining significant popularity. In this work, we adapt the CUDA programming model into a new FPGA design flow called FCUDA, which efficiently maps the coarse and
fine grained parallelism exposed in CUDA onto the reconfigurable fabric. Our CUDA-to-FPGA flow employs AutoPilot, an advanced high-level synthesis tool which enables
high-abstraction FPGA programming. FCUDA is based on a source-to-source compilation that transforms the SPMD CUDA
thread blocks into parallel C code for AutoPilot. We describe the details of our CUDA-to-FPGA flow and demonstrate the highly
competitive performance of the resulting customized FPGA multi-core accelerators. To the best of our knowledge, this is the
first CUDA-to-FPGA flow to demonstrate the applicability and potential advantage of using the CUDA programming model for
high-performance computing in FPGAs.
Abstract: As growing power dissipation and thermal effects disrupted the rising clock frequency trend and threatened to annul Moore’s law, the computing industry has switched its route
to higher performance through parallel processing. The rise of multi-core systems in all domains of computing has opened the
door to heterogeneous multi-processors, where processors of different compute characteristics can be combined to effectively boost the performance per watt of different application kernels.
GPUs and FPGAs are becoming very popular in PC-based heterogeneous systems for speeding up compute intensive kernels of scientific, imaging and simulation applications. GPUs can
execute hundreds of concurrent threads, while FPGAs provide customized concurrency for highly parallel kernels. However, exploiting the parallelism available in these applications is often
not a push-button task. Often the programmer has to expose the application’s fine and coarse grained parallelism by using special APIs. CUDA is such a parallel-computing API that is driven by
the GPGPU industry and is gaining significant popularity. In this work, we adapt the CUDA programming model into a new FPGA design flow called FCUDA, which efficiently maps the coarse and
fine grained parallelism exposed in CUDA onto the reconfigurable fabric. Our CUDA-to-FPGA flow employs AutoPilot, an advanced high-level synthesis tool which enables
high-abstraction FPGA programming. FCUDA is based on a source-to-source compilation that transforms the SPMD CUDA
thread blocks into parallel C code for AutoPilot. We describe the details of our CUDA-to-FPGA flow and demonstrate the highly
competitive performance of the resulting customized FPGA multi-core accelerators. To the best of our knowledge, this is the
first CUDA-to-FPGA flow to demonstrate the applicability and potential advantage of using the CUDA programming model for
high-performance computing in FPGAs.
Project 3 - CS525 Project 3 - Sonar data raytracing using OpenCL
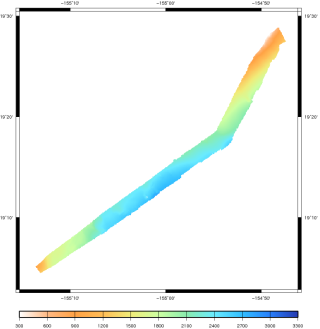 For this project I decided to work on one of the tasks we are currently udertaking as part of the ENDURANCE project.: sonar data raytracing using a sound speed model.
This process is by nature extremely parallel (each sonar ping represents an independent beam to be raytraced), and can greatly benefit from the acceleration that GPU computation can offer.
For this project I decided to work on one of the tasks we are currently udertaking as part of the ENDURANCE project.: sonar data raytracing using a sound speed model.
This process is by nature extremely parallel (each sonar ping represents an independent beam to be raytraced), and can greatly benefit from the acceleration that GPU computation can offer.