Data Science for Librarians Final Project
Using a Naive Bayes Classifier to Sort High-Citation and Low-Citation Articles in the Astrophysics Data System
Key Lessons
- Analysis methods that make use of basic machine learning principles can help you extract meaning from large datasets.
- Obviously, quantitative analysis can't replace an in-depth knowledge of the field you are researching.
- Embrace errors and weird results--they help you understand your code. Also, learn enough about text encodings to tackle the issues that they will invariably produce.
How I Made It
Can you use bibliographic data to predict citation rate? For this project, I collected the 200 most highly cited astronomy journal articles for each year from 1990-2013, and compared them with a random selection of 200 low-citation journal articles from each year in the same range. After stripping punctuation and stopwords I then fed in bigrams from the abstracts, as well as individual words from the titles of the papers, to a Bayes Classifier. Because the prior probabilities were exactly the same in our test (50% high, and 50% low) the Bayes Classifier simply identified terms that were more correlated with high or low citation articles.
Options to sort on author name, author affiliation, keyword, and query term also exist in the code, and using a combination of these filters could yield more interesting results than what I show here.
Disclaimer: No causality is being claimed, and the code is certainly not perfect. There is no normalization for papers with huge numbers of authors, for instance, and on smaller date ranges and more limited queries there is sometimes a problem with over-fitting to the data. Additionally, it is possible that a paper is high citation only because it inspires large-scale disagreement.
Example Queries Using The Code
Among papers mentioning the term dark matter, the presence of which author is most predictive of the paper being high-citation?
According to the classifier, that would be Volker Springel at the Max-Planck-Institute for Astrophysics. (Take author rankings from this code with a grain of salt, however, because no normalization has been done to account for number of authors per paper).
From 1960 to 1980, which title words were indicative of a high- or low-citation paper?
According to the classifier, the words "comet", "ionospheric" and "moon" tended to correlate with low-citation papers during that time, while the words "systems", "evolution", "cluster", and "massive" correlated with high citation papers.
Since 2000, which abstract words correlate with high citation papers about stars?
According to the classifier, the words "NASA" and "GCS" (globular clusters) are strongly correlated with a high citation count for papers discussing stars.
How to Read the Bubble Charts
Below are two bubble charts showing those words and bigrams that the Bayes Classifier found most predictive for classifying an article as low or high citation. The size of the bubble corresponds with the strength of the correlation, and the color (blue for high citation, yellow for low) shows the term's correlation. The numbers in parentheses give an exact account of how many more times you would find the term in a high or low citation paper than the reverse.
As you can see, there were more correlating factors for high citation papers than for low citation papers. Some of the results are completely expected, like the correlation of the bigram “excellent agreement” with high citation papers, and the bigram “preliminary results” with low citation papers. Others require more interpretation. The Python code for the project can be found here.
article title words and citation prevalence
Bayes Classifier Accuracy: 81%
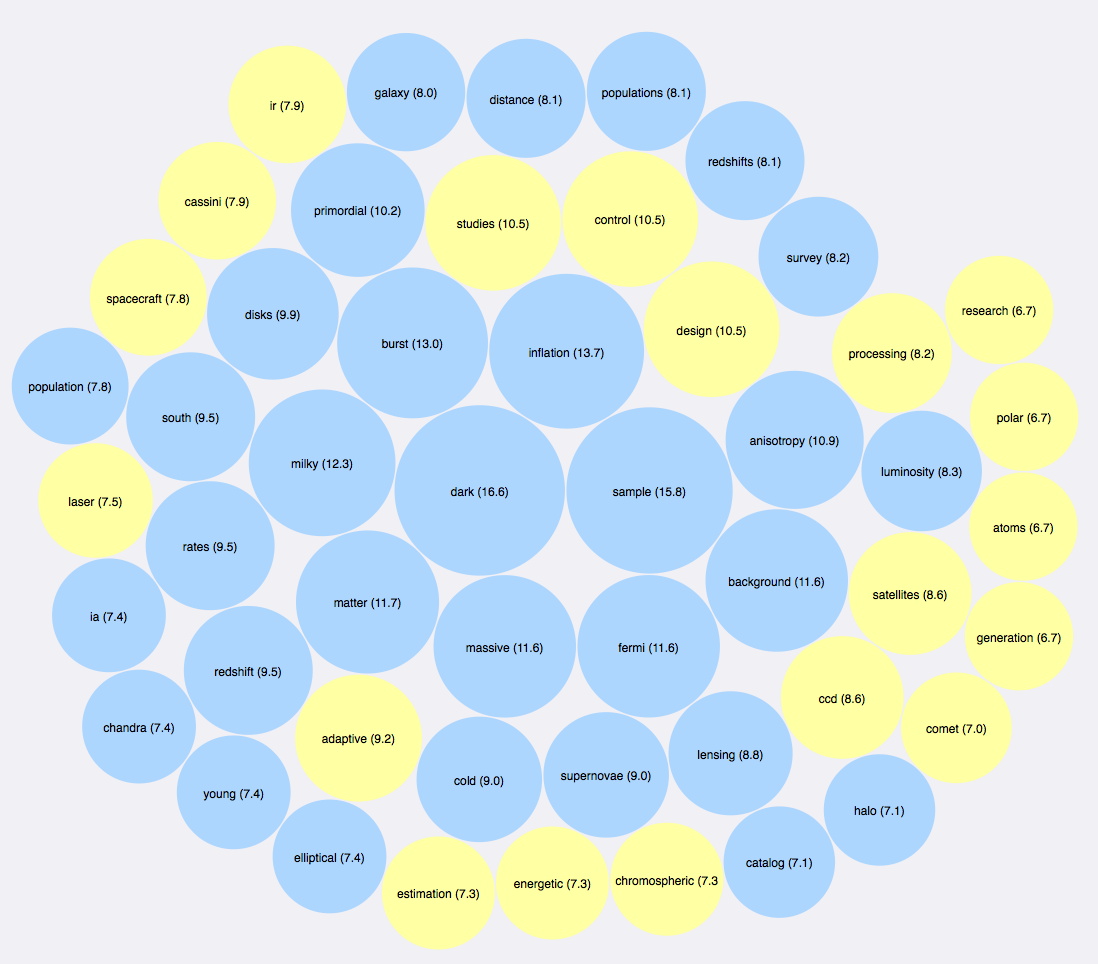
abstract bigrams and citation prevalence
Bayes Classifier Accuracy: 75%
