해석 상세 설정¶
다음은 MLI page 에서 새로운 해석 설정 시 이용할 수 있는 해석 상세 설정 목록입니다. 각 설정의 명칭 앞에는 config.toml 레이블이 붙습니다.
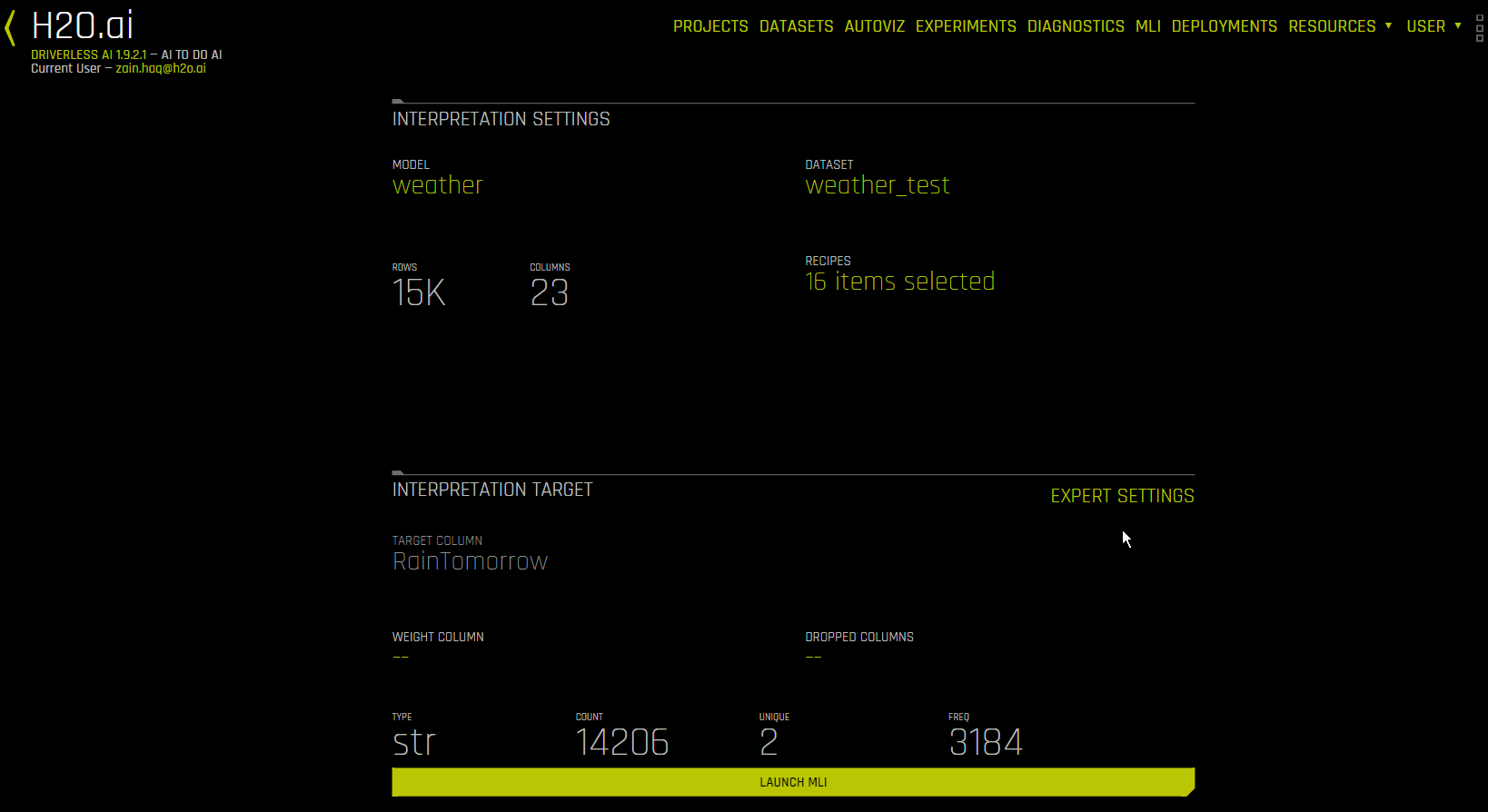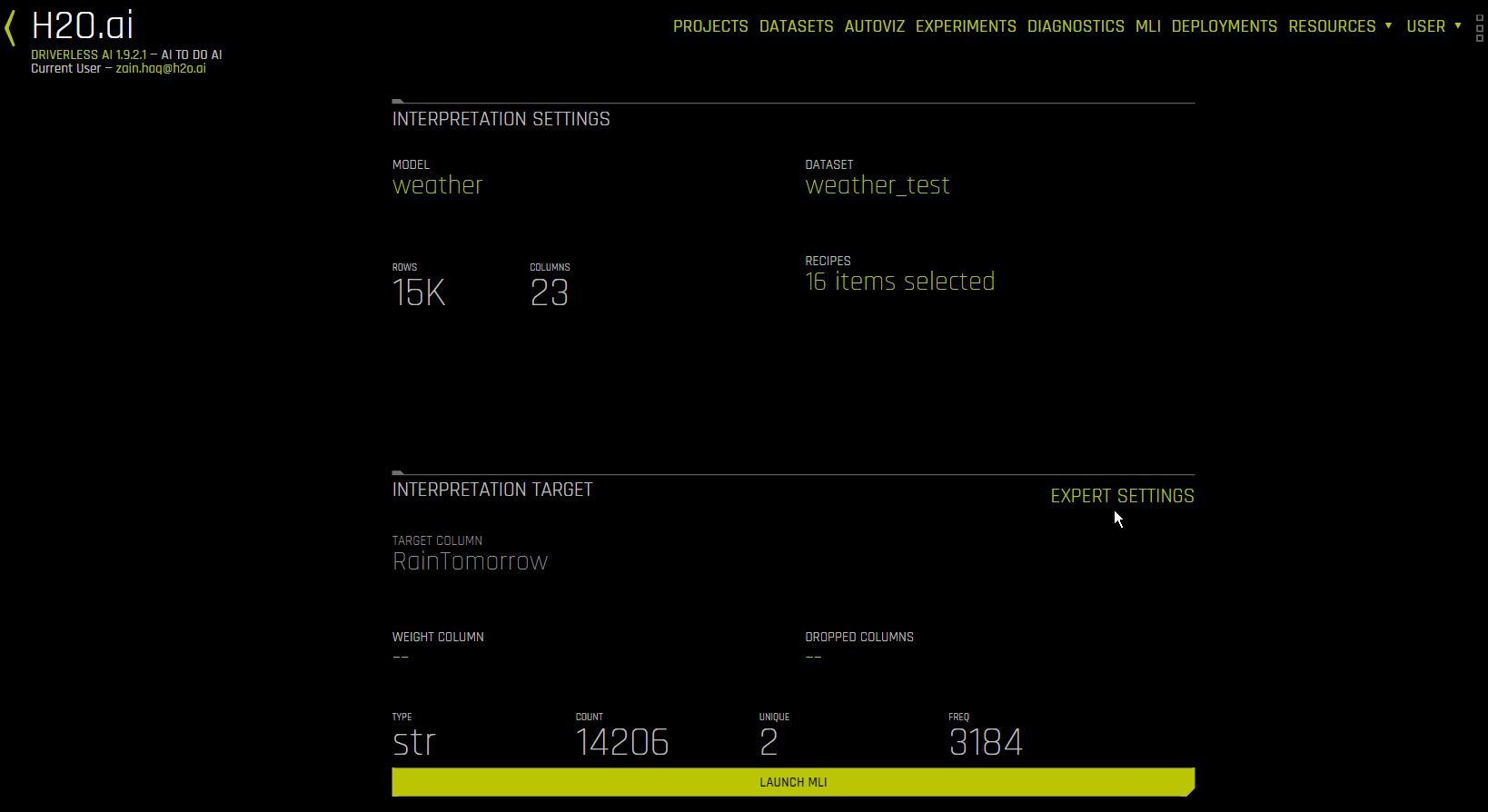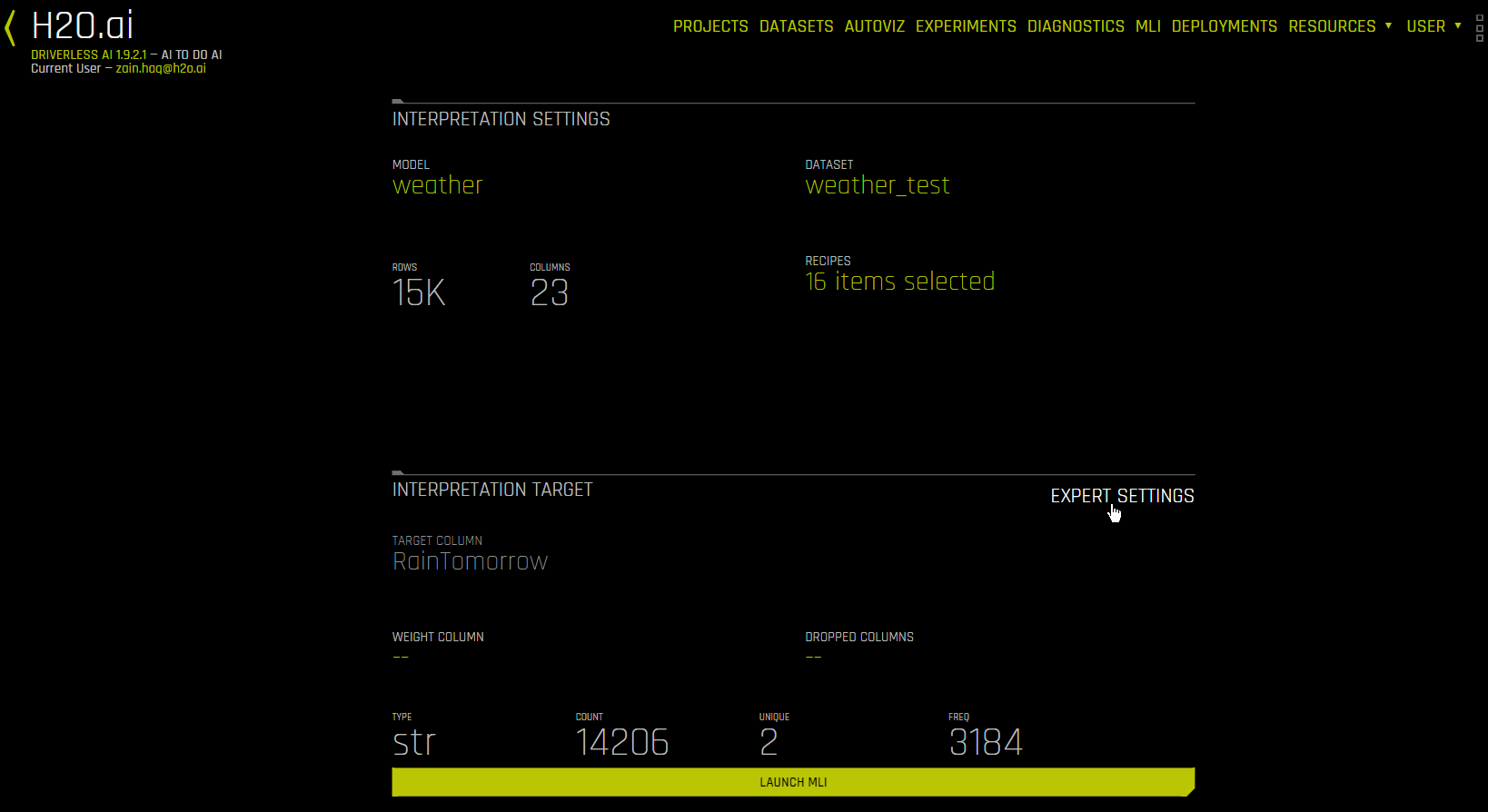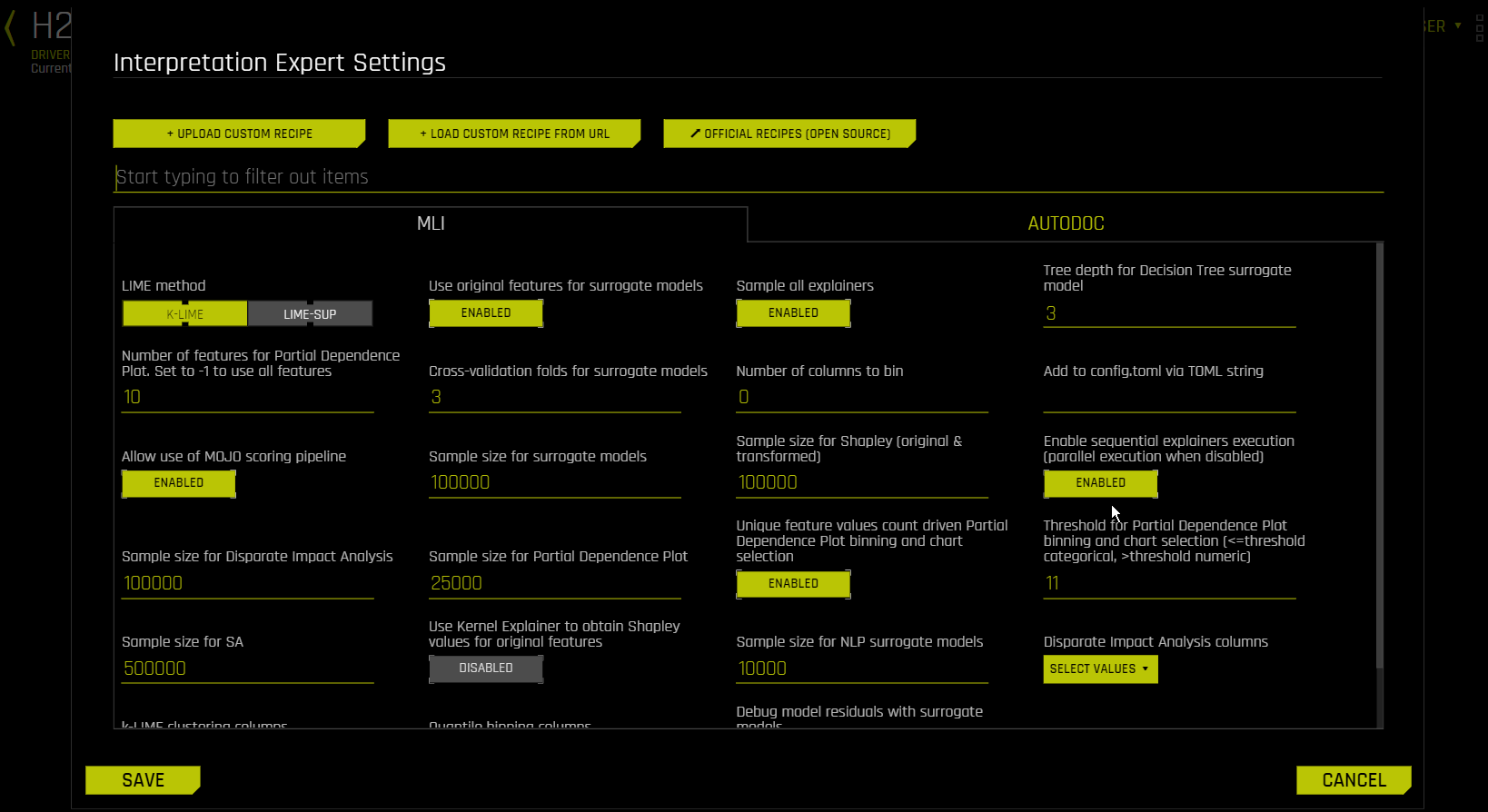
MLI 탭¶
mli_lime_method¶
LIME Method
K-LIME(기본값) 또는 LIME-SUP 중 하나의 LIME 방법을 선택하십시오.
K-LIME (기본값): 전체 학습 데이터에 하나의 글로벌 대리 GLM을 생성하고, 학습 데이터의 k-평균 클러스터에서 형성된 샘플에 많은 로컬 대리 GLM을 생성합니다. k-평균에 사용되는 특성은 Random Forest 대리 모델의 변수 중요도에서 선택됩니다. k-평균에 사용되는 특성의 수는 Random Forest 대리 모델의 변수 중요도에 있는 변수의 상위 25% 중 최솟값이며 k-평균에 사용할 수 있는 변수의 최댓값이며, 이는
mli_max_number_cluster_vars에 대한 config.toml 설정에서 사용자에 의해 설정됩니다(참고로, 데이터 세트의 특성 수가 6 이하일 경우, 모든 특성이 k-평균 클러스터링에 사용됩니다). config.toml 파일의use_all_columns_klime_kmeans를true로 설정하여 k-평균에 대한 모든 특성을 사용할 수 있도록 이전 설정을 끌 수 있습니다. 모든 벌점 GLM 대리는 Driverless AI 모델의 예측을 모델링하도록 학습됩니다. 로컬 설명을 위한 클러스터의 수는 Driverless AI 모델 예측과 모든 로컬 K-LIME 모델 예측 사이의 \(R2\) 가 최대화된 그리드 검색에 의해 선택됩니다. 글로벌 및 로컬 선형 모델의 절편, 계수, \(R2\) 값, accuracy, 예측은 모두 Driverless AI 모델의 행동에 대한 설명의 디버그 및 개발에 사용할 수 있습니다.LIME-SUP: 원변수 측면에서 학습된 Driverless AI 모델의 로컬 영역을 설명합니다. 로컬 영역은 원래 LIME에서와 같이 시뮬레이션 되고 혼란을 주기 위한 관찰 샘플 대신 decision tree 대리 모델의 각 리프 노드 경로에 의해 정의됩니다. 각 영역에 대해 로컬 GLM 모델은 원래 입력값 및 Driverless AI 모델의 예측에 대해 학습됩니다. 그 후, 이 로컬 GLM의 매개변수를 사용하여 Driverless AI 모델에 대한 대략적인 로컬 설명의 생성이 가능합니다.
mli_use_raw_features¶
Use Original Features for Surrogate Models
새로운 해석을 위해 대리 모델에서 원래 특성 또는 변형된 기능의 사용 여부를 지정하십시오. 이것은 기본적으로 활성화되어 있습니다.
Note: 이 설정을 사용하지 않으면 K-LIME 클러스터링 열 및 분위수 비닝 옵션을 사용할 수 없습니다.
mli_sample¶
Sample All Explainers
학습 데이터 샘플에 대한 해석 수행 여부를 지정하십시오. 기본적으로 MLI는 학습 데이터 세트가 10만 행보다 크면 샘플링합니다(등가 config.toml 설정은 mli_sample_size 입니다). 이것은 기본적으로 활성화되어 있습니다. 전체 데이터 세트에 대해 MLI를 실행하려면 이 토글을 끄십시오.
mli_dt_tree_depth¶
Tree Depth for Decision Tree Surrogate Model
KLIME 해석의 경우 decision tree 대리 모델에 대해 원하는 깊이를 지정하십시오. 트리 깊이 값은 2에서 5 사이의 값이 될 수 있으며 기본값은 3입니다. LIME-SUP 해석의 경우 LIME-SUP 트리 깊이를 지정하십시오. 이는 2에서 5 사이의 값이 될 수 있으며, 기본값은 3입니다.
mli_vars_to_pdp¶
Number of Features for Partial Dependence Plot
partial dependence plot의 구축 시 사용할 최대 특성 수를 지정하십시오. -1을 사용하여 모든 특성에 대한 partial dependence plot를 계산하십시오. 기본값은 10입니다.
mli_nfolds¶
Cross-validation Folds for Surrogate Models
사용할 대리 교차 검증 폴드 수를 지정하십시오(0~10). 실험 실행 시, Driverless AI는 학습 데이터를 자동으로 분할하고 검증 데이터를 사용하여 모델 매개변수 튜닝 및 변수 가공 단계의 성능을 결정합니다. 새로운 해석의 경우 Driverless AI는 해석에 기본적으로 3개의 교차 검증 폴드를 사용합니다.
mli_qbin_count¶
Number of Columns to Bin
bin할 열 수를 지정하십시오. 기본값은 0입니다.
mli_custom¶
Add to config.toml via TOML String
이 입력 필드를 사용하여 TOML 문자열을 포함한 Driverless AI 서버 config.toml 구성 파일에 추가하십시오.
mli_enable_mojo_scorer¶
Allow Use of MOJO Scoring Pipeline
이 옵션을 사용하여 MOJO Scoring Pipeline을 비활성화하십시오. 스코어링 파이프라인은 기본적으로(MOJO 및 Python 파이프라인에서) 자동으로 선택됩니다. 특정 모델의 경우 MOJO와 Python에서의 선택이 파이프라인의 성능 및 견고함에 영향을 미칠 수 있습니다.
mli_sample_size¶
Sample Size for Surrogate Models
행의 수가 이 제한 값을 초과하면, 대리 모델을 샘플링합니다. 기본값은 100000입니다.
mli_shapley_sample_size¶
Sample Size for Shapley (Original & Transformed)
행의 수가 이 제한 값을 초과하면, MLI Shapley 계산에 대해 샘플링합니다. 기본값은 100000입니다.
mli_sequential_task_execution¶
Enable Sequential Explainers Execution (Parallel Execution When Disabled)
순차 explainers 수행 활성화 여부를 지정하십시오. 해당 설정은 기본적으로 활성화되어 있습니다. 이 설정이 비활성화되면 병렬 수행이 사용됩니다.
mli_dia_sample_size¶
Sample Size for Disparate Impact Analysis
행의 수가 이 제한 값을 초과하면 Disparate Impact Analysis(DIA)에 대해 샘플링합니다. 기본값은 100000입니다.
mli_pd_sample_size¶
Sample Size for Partial Dependence Plot
행의 수가 이 제한 값을 초과하면, Driverless AI partial dependence plot에 대해 샘플링합니다. 기본값은 25000입니다.
mli_pd_numcat_num_chart¶
Unique Feature Values Count Driven Partial Dependence Plot Binning and Chart Selection
실험에 의해 특성이 수치형 및 범주형 모두로 사용된 경우, PDP 수치형, 범주형 비닝 및 UI 차트 선택 간에 동적 스위칭의 사용 여부를 지정합니다. 이것은 기본적으로 활성화되어 있습니다.
mli_pd_numcat_threshold¶
Threshold for PD/ICE Binning and Chart Selection
Mli_pd_numcat_num_chart 가 활성화되고 고유한 특성 값의 수가 임계값보다 큰 경우, 수치형 비닝 및 차트가 사용됩니다. 그렇지 않으면 범주형 비닝 및 차트가 사용됩니다. 기본 임계값은 11입니다.
mli_sa_sampling_limit¶
Sample Size for Sensitivity Analysis (SA)
행의 수가 이 제한 값을 초과하면 Sensitivity Analysis(SA)에 대해 샘플링합니다. 기본값은 500000입니다.
mli_nlp_sample_limit¶
Sample Size for NLP Surrogate Models
MLI NLP를 수행할 최대 레코드 수를 지정하십시오. 기본값은 10000입니다.
klime_cluster_col¶
k-LIME Clustering Columns
k-LIME 해석의 경우 k-LIME 클러스터링을 적용할 열을 선택적으로 지정하십시오.
Note: 이 설정은 config.toml 파일에서 찾을 수 없습니다.
qbin_cols¶
Quantile Binning Columns
k-LIME 해석의 경우 MLI accuracy에 도움이 되는 십분위수 bin(균등분포)을 생성할 하나 이상의 열을 지정하십시오. 선택된 열은 분위수 비닝 선택을 위해 상위 n개의 열에 추가됩니다. 만약 열이 수치형이 아니거나 데이터 세트(변형된 특성)에 없는 경우, 해당 열을 건너뜁니다.
Note: 이 설정은 config.toml 파일에서 찾을 수 없습니다.
AutoDoc 탭¶
autodoc_report_name¶
AutoDoc Name
AutoDoc의 이름을 지정하십시오.
autodoc_template¶
AutoDoc Template Location
AutoDoc 템플릿 경로를 지정하십시오. 사용자 정의 AutoDoc 템플릿의 전체 경로를 제공합니다. 표준 AutoDoc을 생성하려면, 해당 필드를 비워 둡니다.
autodoc_output_type¶
AutoDoc File Output Type
AutoDoc 파일 출력 유형을 지정하십시오. docx (기본값) 및 md 중에서 선택합니다.
autodoc_subtemplate_type¶
AutoDoc Sub-Template Type
사용할 하위 템플릿 유형을 지정하십시오. 다음 중에서 선택하십시오.
auto(기본값)
md
docx
autodoc_max_cm_size¶
Confusion Matrix Max Number of Classes
혼동 행렬의 최대 클래스 수를 지정하십시오. 기본값은 10입니다.
autodoc_num_features¶
Number of Top Features to Document
문서에 표시할 주요 특성 수를 지정하십시오. 이 설정을 사용하지 않으려면 -1 을 지정하십시오. 기본값은 50입니다.
autodoc_min_relative_importance¶
Minimum Relative Feature Importance Threshold
특성을 표시하려면 최소 상대 특성 중요도를 지정하십시오. 이 값은 float 0 이상 및 1 이하이어야 합니다. 기본값은 0.003입니다.
autodoc_include_permutation_feature_importance¶
Permutation Feature Importance
순열 기반 특성 중요도의 계산 여부를 지정하십시오. 이것은 기본적으로 비활성화되어 있습니다.
autodoc_feature_importance_num_perm¶
Number of Permutations for Feature Importance
특성 중요도 계산 시, 특성 당 생성할 순열의 수를 지정하십시오. 기본값은 1입니다.
autodoc_feature_importance_scorer¶
Feature Importance Scorer
기능 중요도 계산 시, 사용할 scorer의 명칭을 지정하십시오. 실험에 scorer를 사용하려는 경우, 해당 설정을 지정하지 않은 채 그대로 둡니다.
autodoc_pd_max_rows¶
PDP and Shapley Summary Plot Max Rows
AutoDoc에서 partial dependence plot(PDP) 및 Shapley 값 요약 플롯에 대해 표시되는 행 수를 지정하십시오. 무작위 샘플링은 autodoc_pd_max_rows 한계값을 초과하는 데이터 세트에 사용됩니다. 기본값은 10000입니다.
autodoc_pd_max_runtime¶
PDP Max Runtime in Seconds
보고서 생성 시, 부분 의존도 계산에 걸리는 최대 시간(초)을 지정하십시오. 시간 제한이 없는 경우, -1로 설정하십시오.
autodoc_out_of_range¶
PDP Out of Range
partial dependence plot에 포함할 열 범위 밖의 표준 편차 수를 지정하십시오. 이것은 모델이 처음 보는 데이터에 어떻게 반응하는지를 보여줍니다. 기본값은 3입니다.
autodoc_num_rows¶
ICE Number of Rows
개별 행이 지정되지 않은 경우 PDP 및 ICE 플롯에 포함할 행 수를 지정하십시오. 기본값은 0입니다.
autodoc_population_stability_index¶
Population Stability Index
실험이 이진 분류 또는 회귀 분석 문제인 경우 모집단 안정성 지수의 포함 여부를 지정하십시오. 이것은 기본적으로 비활성화되어 있습니다.
autodoc_population_stability_index_n_quantiles¶
Population Stability Index Number of Quantiles
모집단 안정성 지수에 사용할 분위수를 지정하십시오. 기본값은 10입니다.
autodoc_prediction_stats¶
Prediction Statistics
실험이 이진 분류 또는 회귀 분석 문제인 경우 예측 통계 정보의 포함 여부를 지정하십시오. 이것은 기본적으로 비활성화되어 있습니다.
autodoc_prediction_stats_n_quantiles¶
Prediction Statistics Number of Quantiles
예측 통계에 사용할 분위수를 지정하십시오. 기본값은 20입니다.
autodoc_response_rate¶
Response Rates Plot
실험이 이진 분류 문제인 경우 응답 비율 정보의 포함 여부를 지정하십시오. 이것은 기본적으로 비활성화되어 있습니다.
autodoc_response_rate_n_quantiles¶
Response Rates Plot Number of Quantiles
응답 비율 정보에 사용할 분위수를 지정하십시오. 기본값은 10입니다.
autodoc_gini_plot¶
Show GINI Plot
GINI 플롯 표시 여부를 지정하십시오. 이것은 기본적으로 비활성화되어 있습니다.
autodoc_enable_shapley_values¶
Enable Shapley Values
AutoDoc에 Shapley 값 결과의 표시 여부를 지정하십시오. 이것은 기본적으로 활성화되어 있습니다.
autodoc_global_klime_num_features¶
Global k-LIME Number of Features
k-LIME 글로벌 GLM 계수 테이블에 표시할 특성 수를 지정하십시오. 이 값은 0 또는 -1보다 큰 정수이어야 합니다. 모든 특성을 표시하려면, 이 값을 -1로 설정하십시오.
autodoc_global_klime_num_tables¶
Global k-LIME Number of Tables
AutoDoc에 표시할 k-LIME 글로벌 GLM 계수 테이블 수를 지정하십시오. 계수가 절댓값으로 정렬된 한 개의 테이블을 표시하려면, 이 값을 1로 설정하십시오. 이 값을 2로 설정하여 상위 양의 계수가 있는 테이블과 상위 음의 계수가 있는 두 개의 테이블을 표시합니다. 기본값은 1입니다.
autodoc_data_summary_col_num¶
Number of Features in Data Summary Table
데이터 요약 테이블에 표시할 기능 수를 지정하십시오. 이 값은 정수여야 합니다. 모든 열을 표시하려면 1보다 작은 값을 지정하십시오. 기본적으로 -1로 설정됩니다.
autodoc_list_all_config_settings¶
List All Config Settings
모든 config 설정의 표시 여부를 지정하십시오. 비활성화된 경우 변경된 설정만 나열됩니다. 활성화되면 모든 설정이 나열됩니다. 이것은 기본적으로 비활성화되어 있습니다.
autodoc_keras_summary_line_length¶
Keras Model Architecture Summary Line Length
Keras 모델 아키텍처 요약의 라인 길이를 지정하십시오. 이 값은 0 또는 -1보다 큰 정수이어야 합니다. 기본 라인 길이를 사용하려면 이 값을 -1(기본값)로 설정하십시오.
autodoc_transformer_architecture_max_lines¶
NLP/Image Transformer Architecture Max Lines
특성 섹션에서 고급 트랜스포머 아키텍처에 대해 표시되는 최대 라인 수를 지정하십시오. 전체 아키텍처는 부록에서 확인할 수 있습니다.
autodoc_full_architecture_in_appendix¶
Appendix NLP/Image Transformer Architecture
부록에 전체 NLP/Image 트랜스포머 아키텍처의 표시 여부를 지정하십시오. 이것은 기본적으로 비활성화되어 있습니다.
autodoc_coef_table_appendix_results_table¶
Full GLM Coefficients Table in the Appendix
부록에 전체 GLM 계수 테이블의 표시 여부를 지정하십시오. 이것은 기본적으로 비활성화되어 있습니다.
autodoc_coef_table_num_models¶
GLM Coefficient Tables Number of Models
AutoDoc에 GLM 계수 테이블이 표시되는 모델의 수를 지정하십시오. 이 값은 -1 또는 1 이상의 정수이어야 합니다. 모든 모델에 대해 테이블을 표시하려면 이 값을 -1로 설정하십시오. 기본값은 1입니다.
autodoc_coef_table_num_folds¶
GLM Coefficient Tables Number of Folds Per Model
AutoDoc에 GLM 계수 테이블이 표시되는 모델당 폴드 수를 지정하십시오. 이 값은 -1(기본값) 또는 1 이상의 정수이어야 합니다 (-1은 모델당 모든 폴드를 표시함).
autodoc_coef_table_num_coef¶
GLM Coefficient Tables Number of Coefficients
AutoDoc의 GLM 계수 테이블에 표시할 계수의 수를 지정하십시오. 기본값은 50입니다. 모든 계수를 표시하려면 이 값을 -1로 설정하십시오.
autodoc_coef_table_num_classes¶
GLM Coefficient Tables Number of Classes
AutoDoc의 GLM 계수 테이블에 표시할 클래스의 수를 지정하십시오. 모든 클래스를 표시하려면, 이 값을 -1로 설정하십시오. 기본값은 9입니다.
autodoc_num_histogram_plots¶
Number of Histograms to Show
히스토그램을 표시할 상위 특성의 수를 지정하십시오. 기본값은 10입니다.