| Exercise 3 | Crime Mapping Data Request |
| Data | Roads (AutoCAD DWG) Crime Statistics (CSV) |
| Overall Goal | Carry out a join between crime statistics and city block |
| Demonstrates | Attribute-Based Joins |
| Start Workspace | None |
| End Workspace | C:\FMEData2016\Workspaces\DesktopBasic\Transformers-Ex3-Complete.fmw C:\FMEData2016\Workspaces\DesktopBasic\Transformers-Ex3-Complete-Advanced.fmw |
A data journalist with a national newspaper has made a request for spatial data showing the location of crime within the city on a block-by-block basis. It's partly a test of the city's open data policy and there's no question of not complying.
However, a crisis arises as the current datasets for crime (CSV, non-spatial) and city blocks (AutoCAD) are not joined in any way!
You hear about the problem and suggest that FME can create a join between the crime figures and city blocks so that the information can be provided in the format requested. Pull this off and you will be a spatial superhero!
1) Inspect Source Data (Crime)
The first task is to familiarize yourself with the source data. To do this open the following dataset within the FME Data Inspector or a simple text editor.
| Reader Format | Comma Separated Value (CSV) |
| Reader Dataset | C:\FMEData2016\Data\Emergency\Crime2011.csv |
| Reader Parameters | File Has Field Names: Yes (Checked) Lines to Skip: Header 1 |
The data will look like this in the Data Inspector Table View window:
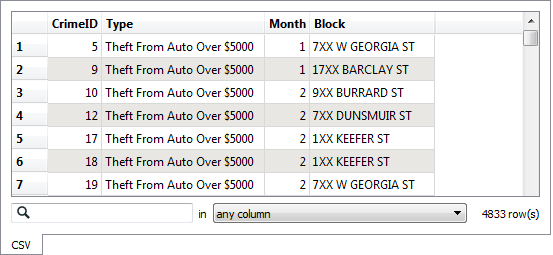
Notice how there is no spatial data as such, but there is a block number.
| Police-Chief Webb-Mapp says... |
| Crime?! In my city? I think not. But if there was... be aware that 7XX W Georgia Street means the seventh block on Georgia Street west of Ontario Street and covers building numbers 700-800. 7XX E Georgia Street would be 14 blocks away, the seventh block east of Ontario. Got it? |
2) Inspect Source Data (Roads)
Now let's inspect some spatial data that we can merge the crime statistics onto. Open the following dataset in the Data Inspector
| Reader Format | Autodesk AutoCAD DWG/DXF |
| Reader Dataset | C:\FMEData2016\Data\Transportation\Roads.dwg |
| Reader Parameters | Group Entities By: Attribute Schema |
This is a dataset of roads. You'll see that the roads are split up at the junction of each city block, which is perfect for our purposes. It too has a block number attribute:

One difference that will make the join harder is that the block number is padded with zeros ("700" instead of "7XX"). Another difference is that the road data is stored in Title case ("W Georgia St") in the roads dataset, whereas the crime dataset is upper case ("W GEORGIA ST").
3) Add Readers
Now let's start working with this data. Start FME Workbench and begin with a blank canvas.
Add a Reader to the workspace using Readers > Add Reader from the menubar. This Reader should be used to read the crime (CSV) data. Be sure to use the same parameters as specified for the Data Inspector.
Now add a second Reader to read the roads (DWG) data. However, from inspecting the data, I see that the roads are stored on a set of seven different layers. We don't need that, so set the "Single Merged Feature Type" parameter when adding the Reader, like so:
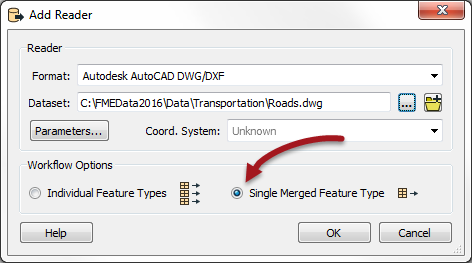
Again, be sure to use the same Group Entities By parameter as specified for the Data Inspector.
The workspace will now look like this:
If you don't click the Single Merged Feature Type option you'll get a feature type for each AutoCAD layer. That's OK, but you'll have to make sure you connect each of them to the subsequent transformers.
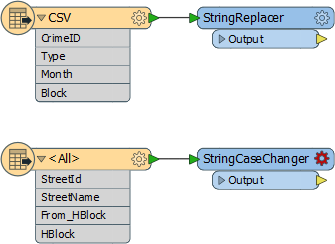
4) Add StringReplacer
To merge the data we need a common block attribute. The current difference in how the block number is structured can be fixed very simply by replacing "XX" with "00" using a StringReplacer transformer.
Add a StringReplacer transformer and connect it to the Crime dataset feature type.
Open the parameters dialog for the StringReplacer. Set the proper parameters. The Attribute to process will be "Block", the Text to Match will be "XX" and the Replacement Text will be "00", like so:
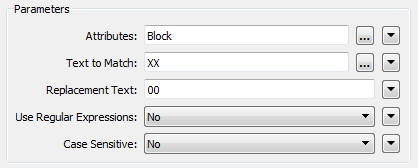
Click OK to accept the values. If you wish, attach Inspector transformers and run the workspace to ensure the transformer is working as expected.
5) Add StringCaseChanger
The other difference in crime/road data was in UPPER/Title case street names. This disparity can be fixed with a StringCaseChanger transformer.
Add a StringCaseChanger transformer and connect it to the roads dataset feature type:
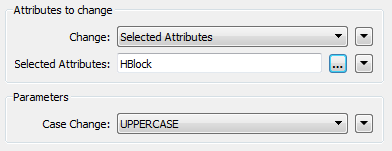
Open the parameters dialog. Set the parameters to change the values of HBlock to upper case:
| Miss Vector says... |
| So, answer me this. Why do we use the StringCaseChanger on the roads data (to UPPERCASE) rather than changing the crime data (to TitleCase)? Do you know? |
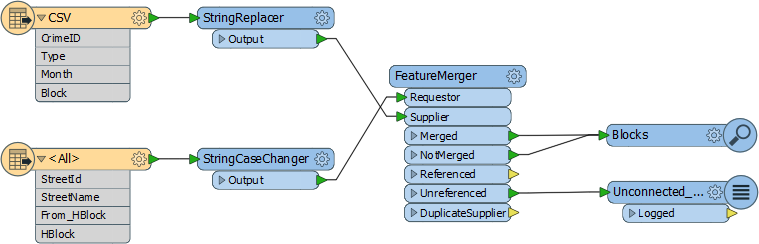
6) Add FeatureMerger
Now we've sorted out the structure of our join keys we can merge the data together with a FeatureMerger.
Add a FeatureMerger to the canvas. Connect the roads data as the Requestor and the crime data as the Supplier (we wish to supply the roads data with crime statistics):
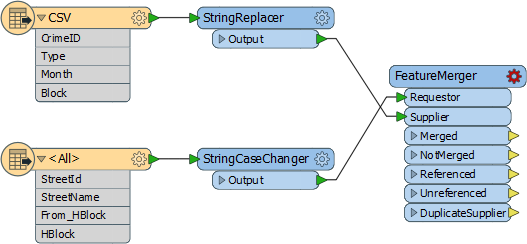
If, like me, you don't like connections that cross over, feel free to swap the position of the objects around to untangle it.
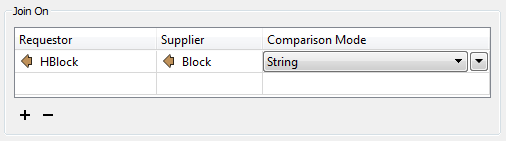
Open the parameters dialog for the FeatureMerger.
For the "Join On" set of parameters, the Requestor join attribute will be HBlock, the Supplier join attribute will be Block, and the Comparison Mode will be String:
| Dr Workbench says... |
|
If you are sharp, you may have noticed that the Requestor and Supplier parameters can be defined within a text edit window.
That means, instead of using the transformers we just added, we could replicate their functionality using functions inside that text editor, like so: @ReplaceString(@Value(Block),XX,00) @UpperCase(@Value(HBlock)) |
For the "Merge Parameters" the Feature Merge Type should be Attributes Only. Because we can expect multiple crimes per block the parameter Process Duplicate Suppliers should be set to Yes. Set the Number of Suppliers Attribute to be "NumberOfCrimes" - this will create an attribute of that name recording how many crimes occurred in that block.
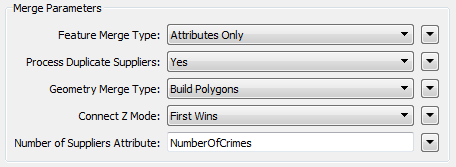
Finally, the attribute accumulation needs to be "Merge Supplier."
Click OK to close the dialog.
7) Add Inspectors
Add Inspector transformers to the Merged and NotMerged output ports (or connect both outputs to one Inspector). This will give us the roads data with crime info attached. The NotMerged data is important because there may be blocks without any crime.
The Unreferenced output port will show us crimes that didn't match to a known address, so connect a Logger transformer here to record any features that fail in this respect.
8) Save and Run Translation
Save the workspace and then run the translation. By querying a block you should be able to see how many crimes took place there.
| TIP |
| If you want to see a list of crimes that took place in each block, open the FeatureMerger parameters and check the box to Generate List. Now re-run the workspace and query a feature (the list won't show up in the table view window). |
| Advanced Exercise |
| You've now successfully merged crime statistics onto a set of spatial data, which is what the data journalist was asking for. However, if he can create a map from that information, then so can we. If you have time, let's give it a try. |
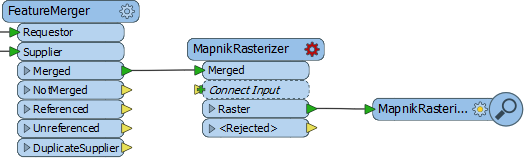
9) Add MapnikRasterizer
The MapnikRasterizer is a way of creating nicely formatted raster map output from a set of vector data.
Place a MapnikRasterizer transformer connected to the Merged output port of the FeatureMerger:
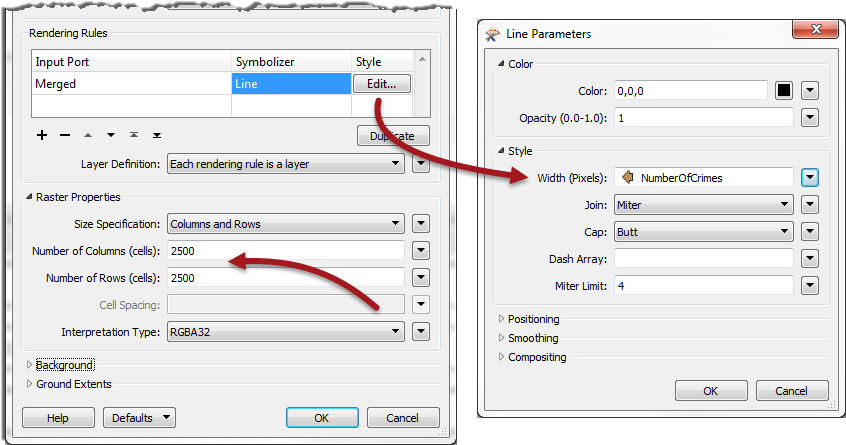
Open the parameters dialog. Set the Merged layer to be a Line symbolizer. Then click the Edit button to the right.
For the Line Width (pixels) parameter click the drop down arrow and select Attribute Value > Number of Crimes. Click OK to close the dialog.
Set the output raster size to be 2500 cells for both Columns and Rows.
10) Add RasterExpressionEvaluator
If you run the workspace now you will see a white square containing black "features". To see the background map through the white area we can set the transparency of the white data.
To do this, add a RasterExpressionEvaluator transformer. Open the parameters dialog and set the parameters as follows:
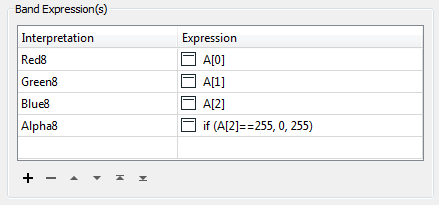
This basically means set the Red-Green-Blue values as they were before. If the blue value was 255 then set transparency to 0, else set it to 255. i.e. If the area is white, then set it to transparent.
11) Run Workspace
Now you can add an Inspector and run the workspace.
The output will look like this:
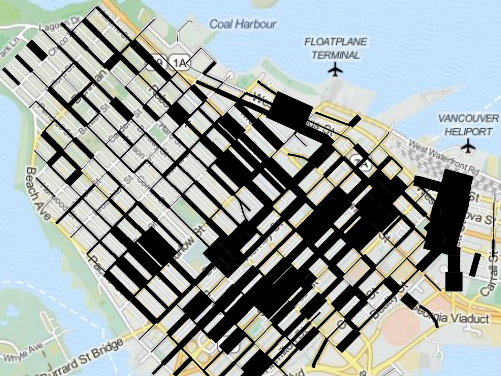
Tiles Courtesy of MapQuest
Basically we've created a map where road width reflects the amount of crime on that block.
| CONGRATULATIONS |
By completing this exercise you have learned how to:
|