Driverless AI 图像处理¶
Driverless AI 图像处理是一款功能强大的工具,可用于从数字图像中获得见解。本节介绍 Driverless AI 的图像处理功能。
Uploading Image dataset 至 Driverless AI。
Image Transformer:当除了其他特征类型外,数据集还有一个特征是图像时,可使用图像转换器。
Image Model:当数据集的唯一特征是图像时,可构建图像模型。
Deploy Image model 至生产环境。
上传数据以进行图像处理¶
Driverless AI 支持多种图像数据集上传方法:
图像按类别存储在目录中的存档。根据目录层次自动创建每个类别的标签。
图像和 CSV 文件的存档,此 CSV 文件包含至少一个有相对图像路径的列和一个目标列(回归实验的最佳方法)
带有磁盘上图像本地路径的 CSV 文件
带有图像远程 URL 的 CSV 文件
构建图像模型¶
Driverless AI 有两种不同的构建图像模型的方法。
嵌入向量转换器 (Image Vectorizer)¶
Image Vectorizer transformer 可使用预训练的 ImageNet 模型将具有图像路径或 URL 的列转换为嵌入(向量)表示形式(衍生自模型的最后一个全局平均池化层)。所得到的向量用于 Driverless AI 中的建模。
专家设置 面板中有几个选项可允许您配置 Image Vectorizer 转换器。可在实验页面中评分器旋钮的上方找到此面板。请参阅 Image Settings ,了解更多关于这些选项的信息。
请注意:
此种建模方法支持分类和回归实验。
此种建模方法支持使用混合数据类型(任何数量的图像列、文本列、数值列或分类列)
自动图像模型¶
自动图像模型是一种 AutoML 模型,仅接受一个图像和一个标签作为输入特征。此模型会自动选择超参数,例如学习率、优化器、批处理大小和图像输入大小。它还通过选择时期数、裁剪策略、增强和学习率调度器来使训练进程自动化。
自动图像模型使用预训练的 ImageNet 模型并从中启动训练进程。可用的架构列表包括所有大家熟知的模型:(SE)-ResNe(X)ts、DenseNets、EfficientNets、EfficientNets 等。
独特见解可为当前最佳个体模型提供信息和样本图像,因而适用于自动图像模型。若需查看这些见解,可在实验运行时或实验结束后点击 见解 选项。更多信息,请参阅 ImageAuto 模型见解.
每个个别模型的评分(以及神经网络架构名称)均可在“迭代数据”面板中找到。迭代数据的最后一个点始终为 ENSEMBLE_TTA。这表明最终模型集成了多个个体模型并应用了测试时增强 (TTA)。
启用自动图像模型
若需启用自动图像模型,可导航至 pipeline-building-recipe 专家设置,然后选择 image_model 选项:
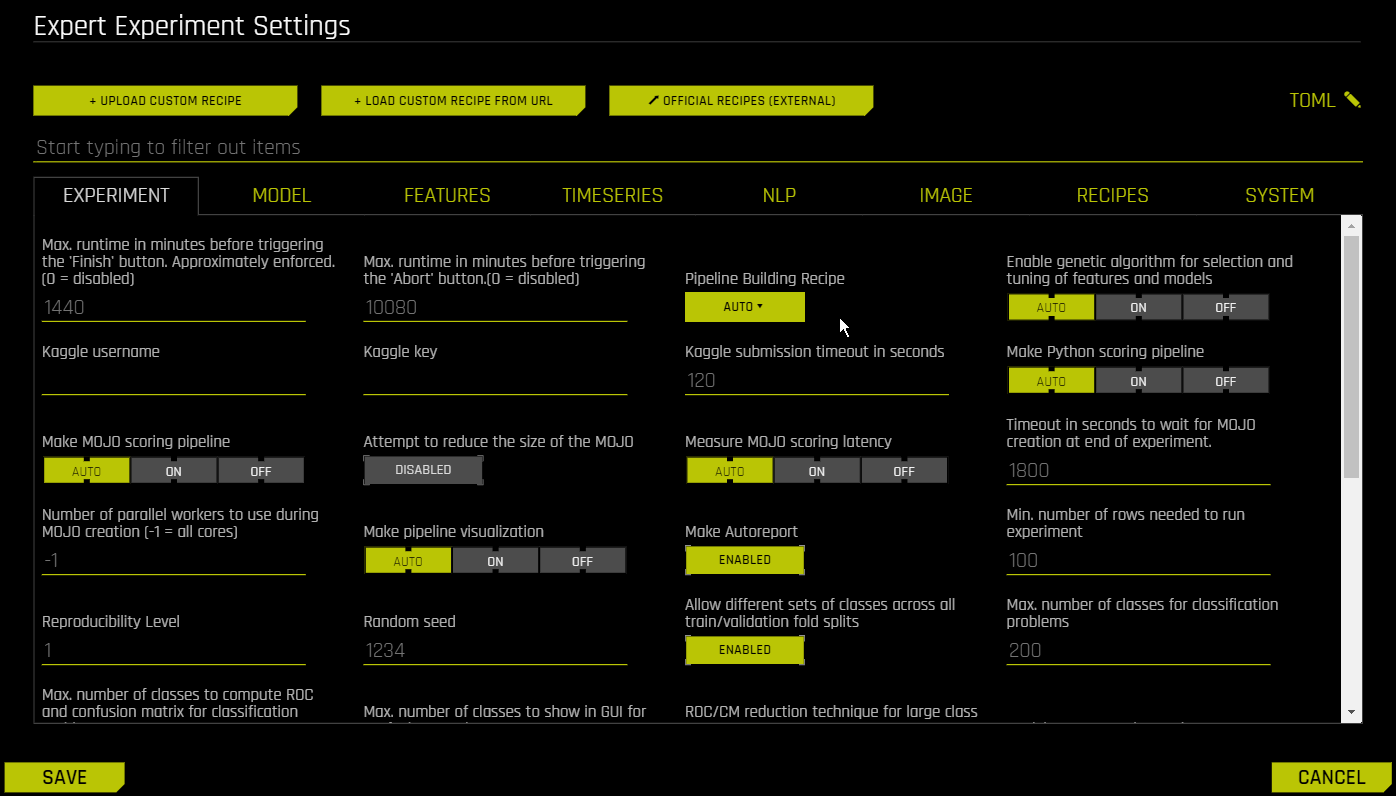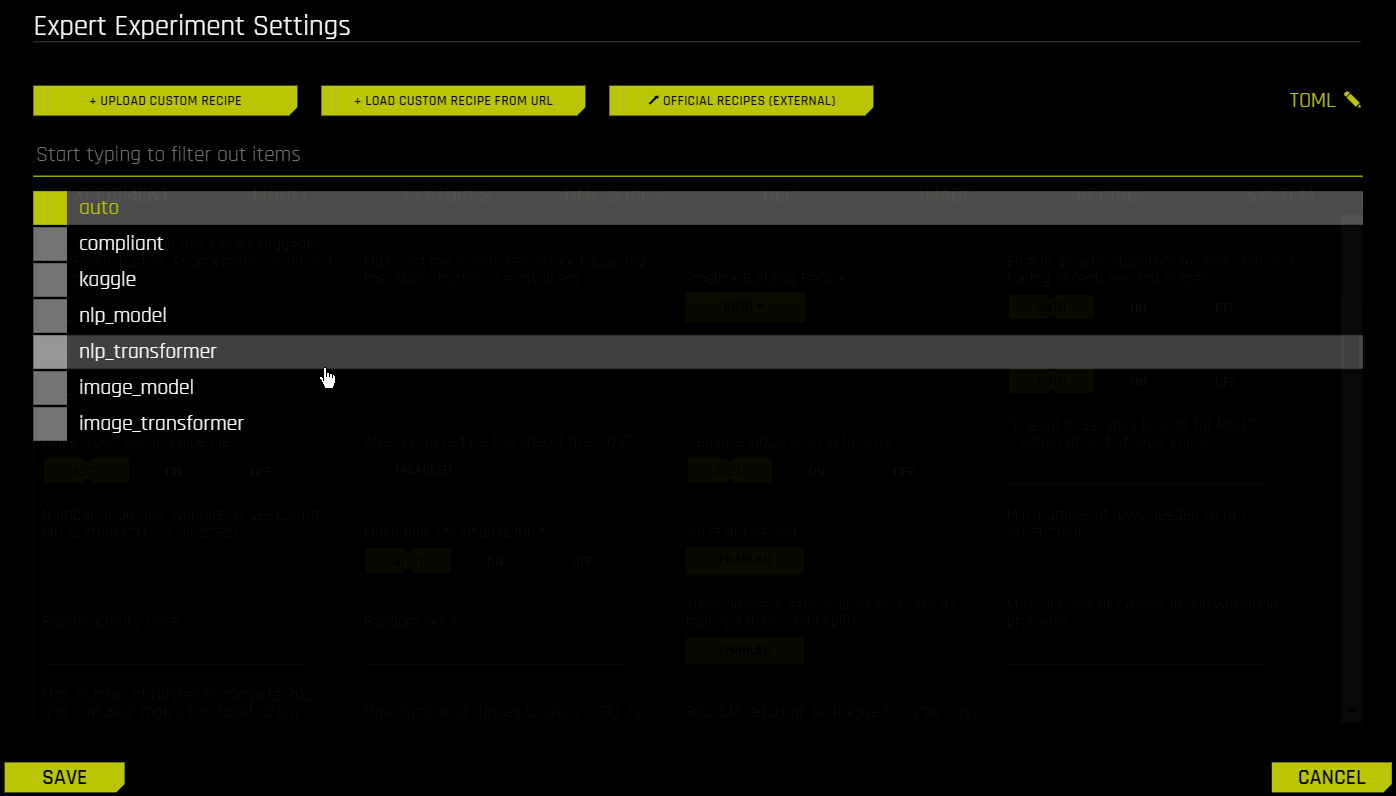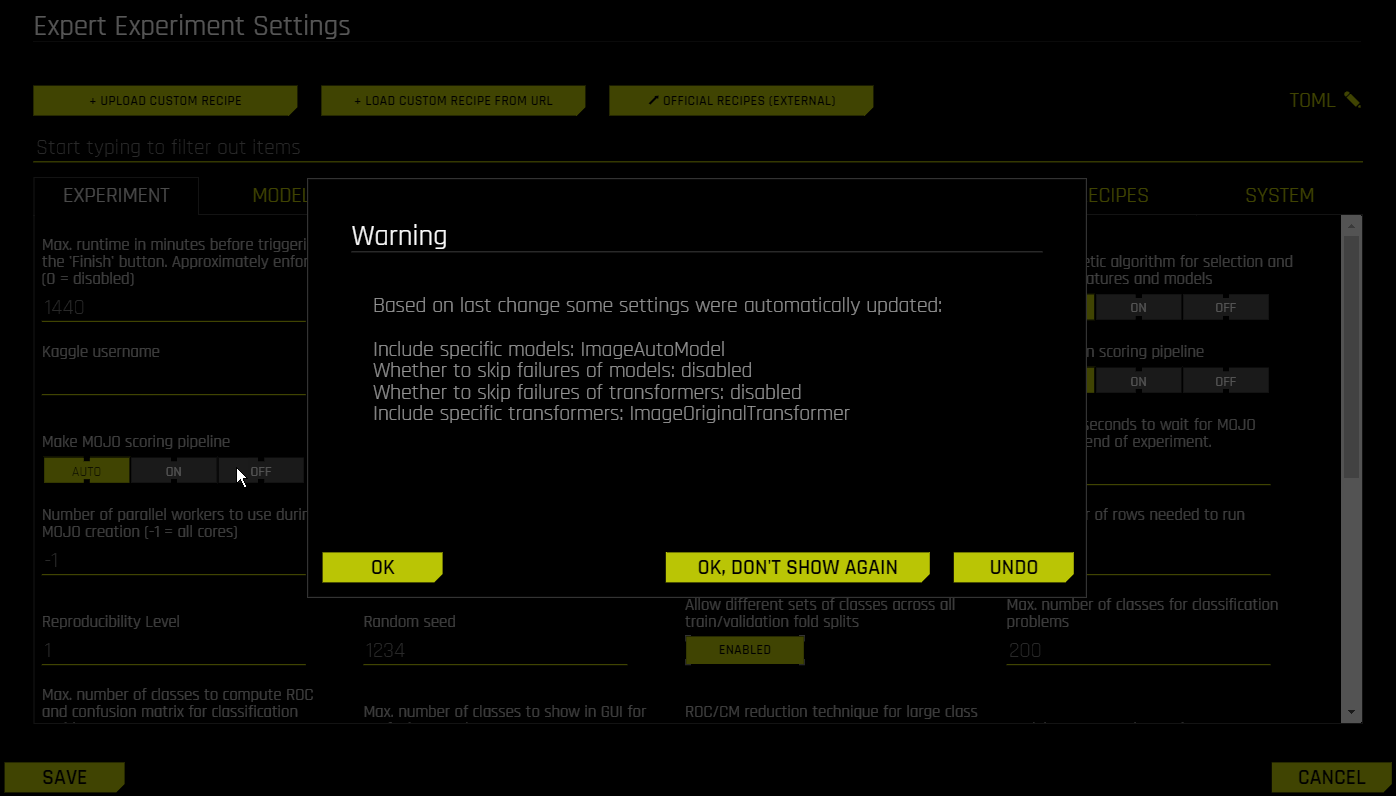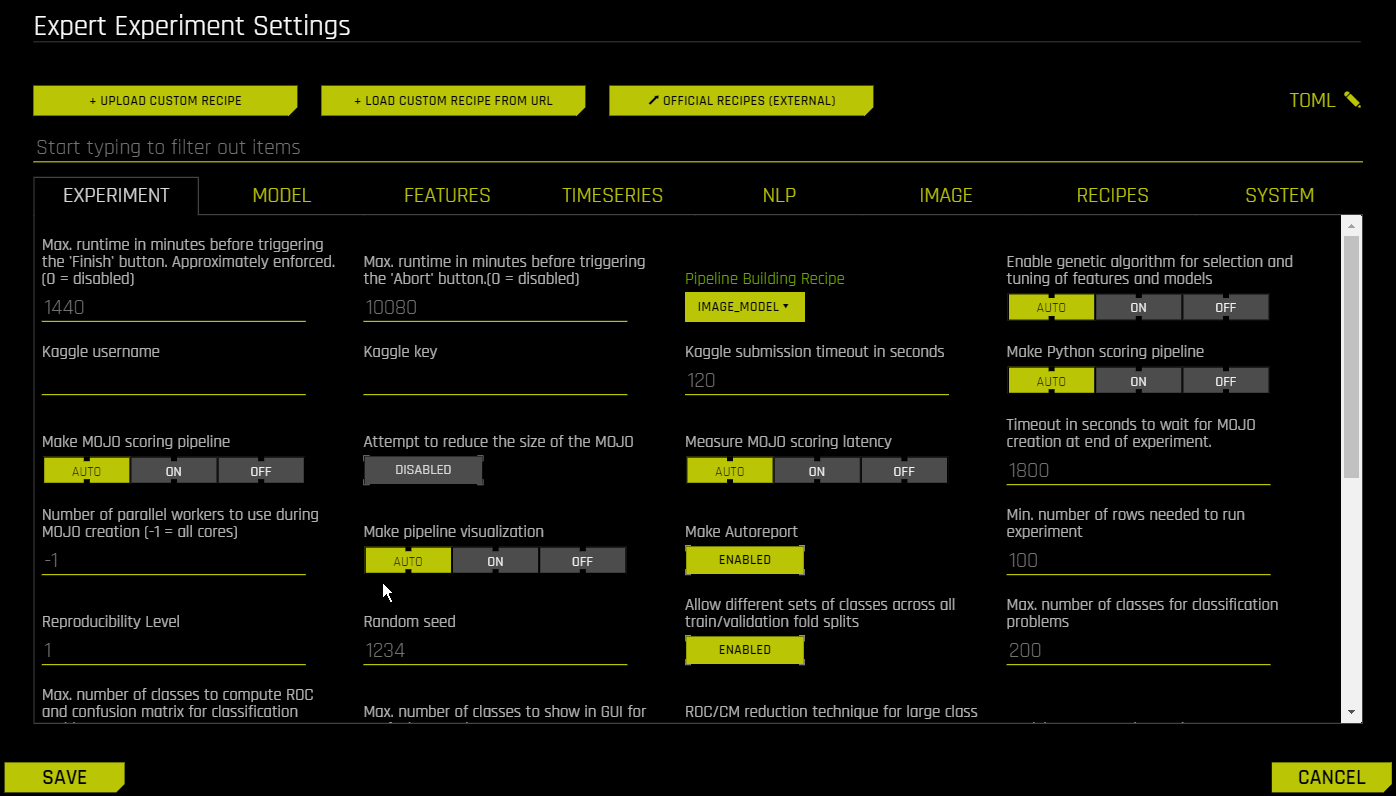
确认选择后,点击 保存 。实验预览部分将进行更新,以包含关于自动图像模型的信息:
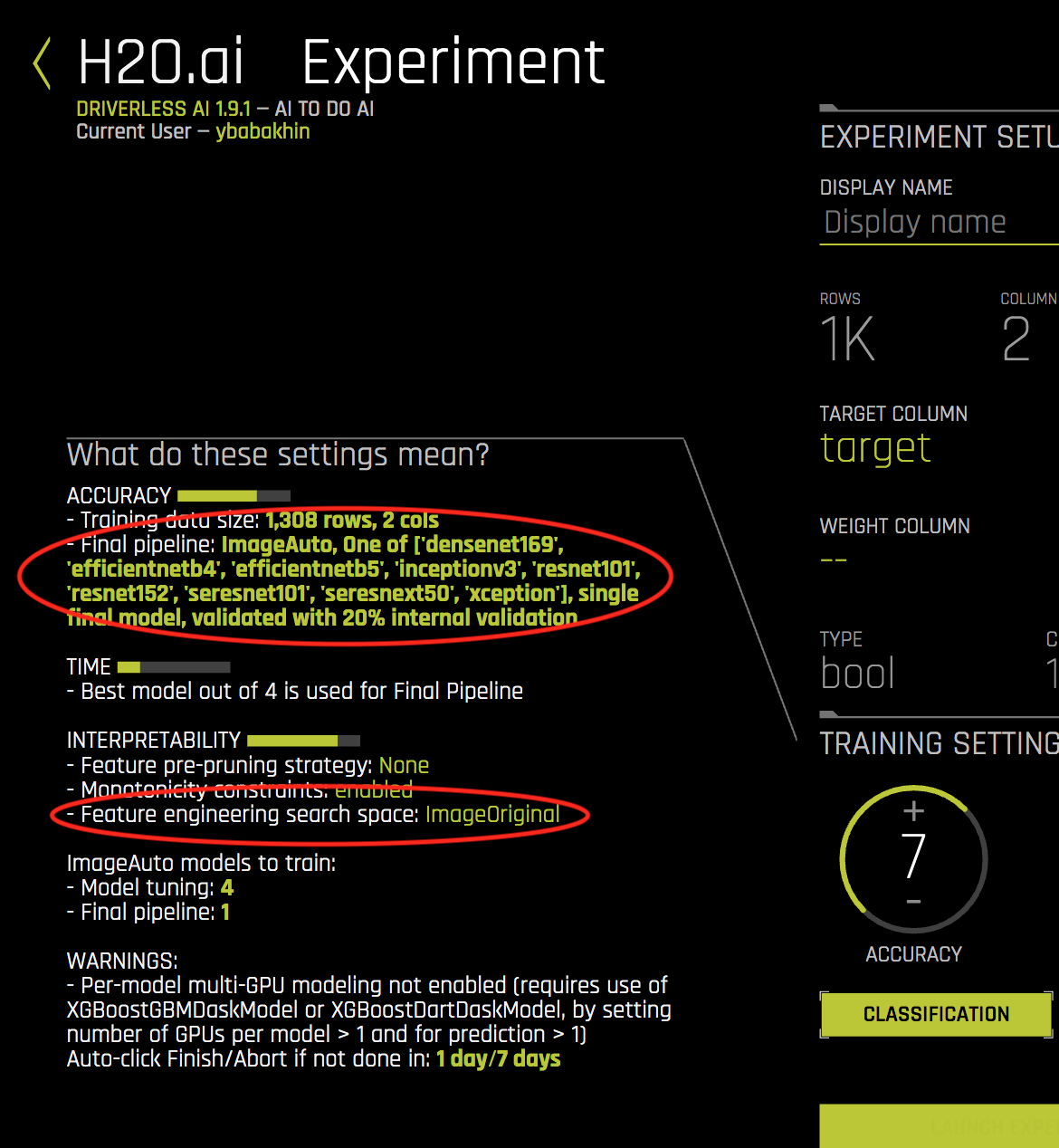
请注意:
此种建模方法仅支持输入单个图像列。
此种建模方法不支持任何转换器。
此种建模方法支持分类和回归实验。
由于对输入特征有所限制,此种建模方法不支持使用混合数据类型。
此种建模方法未使用遗传算法 (GA)。
强烈建议为此种建模方法使用一个或多个 GPU。
如果已连接互联网,则会自动下载 ImageNet 预训练权重。如果未连接互联网,则必须从 http://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/pretrained/autoimage_weights.zip 下载权重,并将其提取至
./tmp或tensorflow_image_pretrained_models_dir(在 config.toml 文件中指定)。
部署图像模型¶
image transformer 支持使用 Python scoring 和 C++ MOJO scoring . 目前, image models 仅支持使用 Python 评分管道。