Initiating Failover Live
During a failover, the virtual machines in the virtual protection group (VPG) or specific virtual machines in a virtual protection group (VPG) are replicated to a set checkpoint in the recovery site. As part of the process you can also set up reverse protection to create a VPG on the recovery machine for the virtual machines being replicated, pointing back to the protected site.
You can initiate a failover to the last checkpoint recorded in the journal, even if the protected site is no longer up.
You can initiate a failover during a test, as described in Initiating Failover Live During a Test.
If you have time, you can initiate the failover from the protected site. However, if the protected site is down, you initiate the failover from the recovery site. You cannot select specific VMs in a VPG for failover if the protected site is down.
|
Note:
|
Any VPGs in the process of being synchronized cannot be recovered, except in the case of bitmap synchronization. |
To initiate failover live:
|
1.
|
In the left pane of the Zerto User Interface, click Failover and then select Live. |
The Failover Live wizard is displayed.
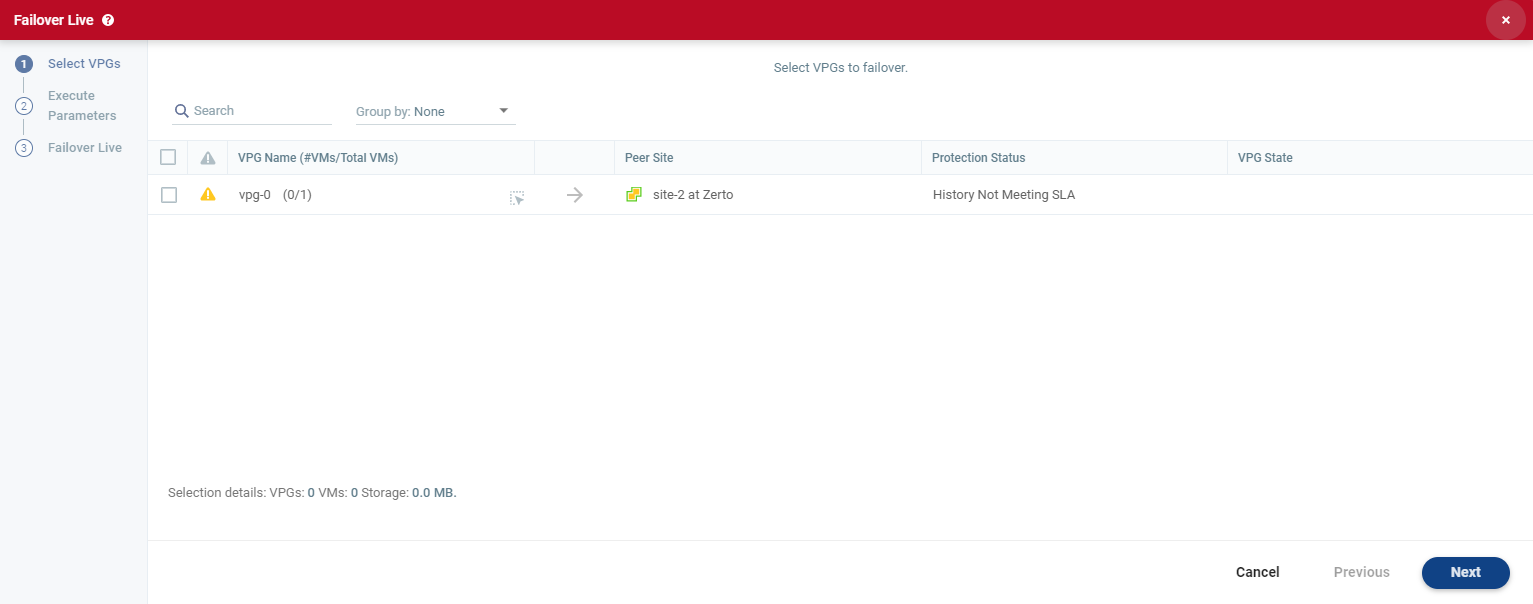
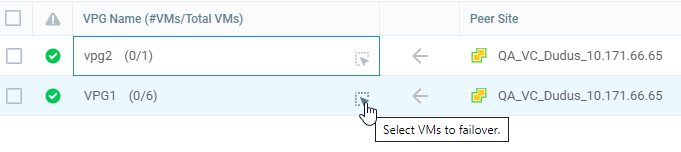
| 2. | Select the VPGs to failover. By default, all VPGs are listed. |
The arrow shows the direction of the process: from the protected site to the peer (recovery) site.
You can select specific VMs to failover.
| • | Selecting specific VMs in a VPG to failover is not supported when replicating from a vCD site. |
| • | VM selection is not available when there is only one VM. |
| a. | To select specific VMs in a VPG, click the icon next to the VPG. |
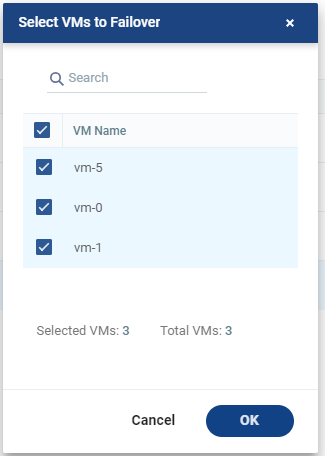
The Select VMs to Failover dialog is displayed. By default, all VMs are selected when the VPG is selected.
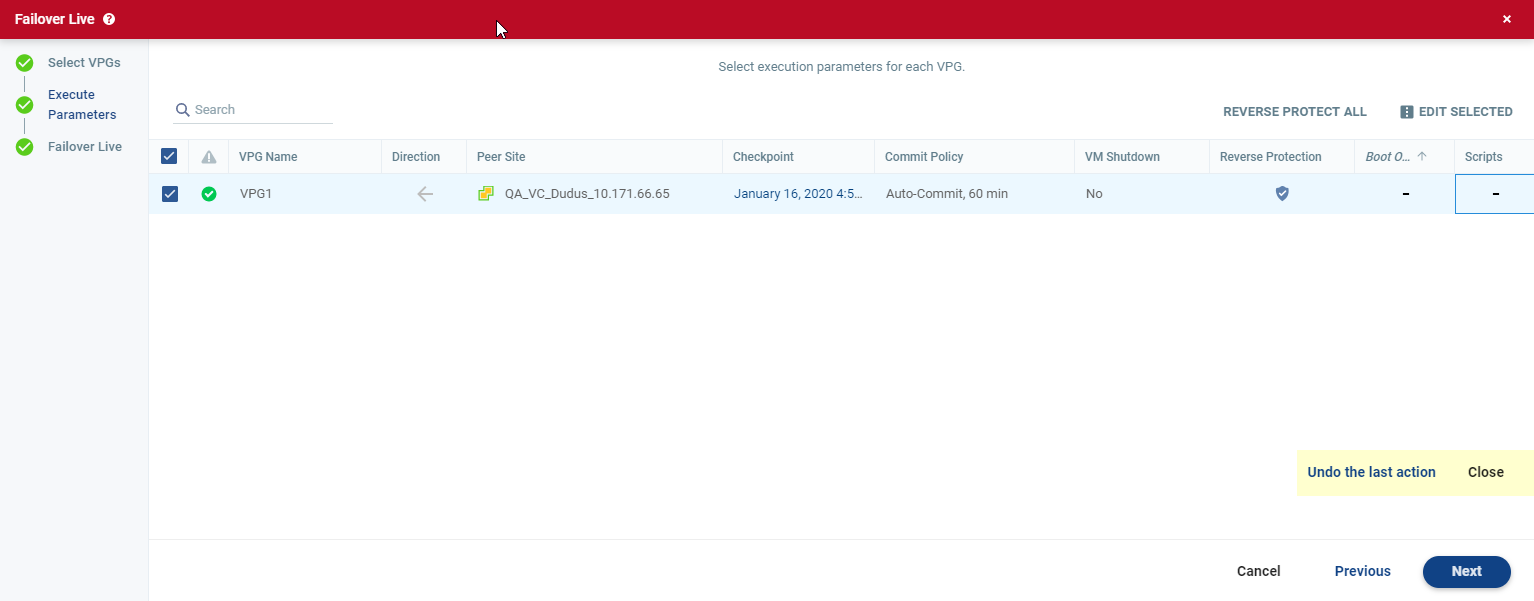
The Execute Parameters step is displayed.
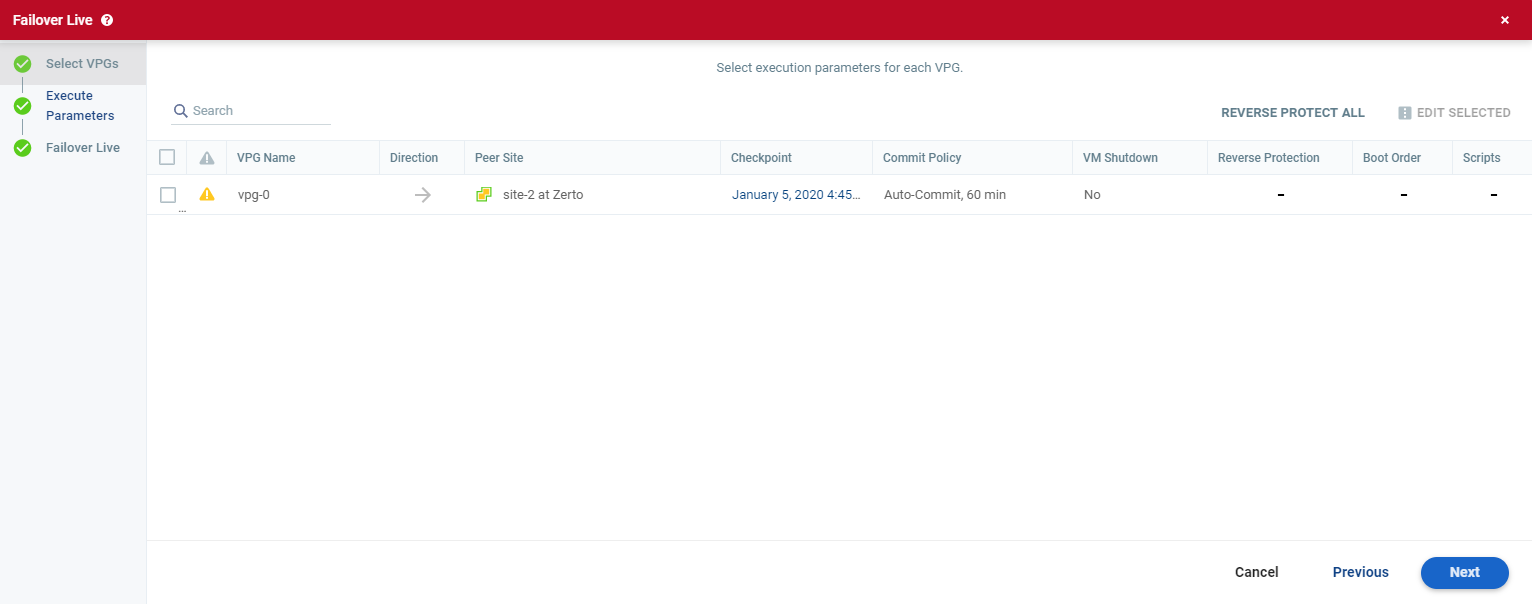
You can see if a boot order and scripts are defined for the VPG and you can change the following parameters:
Once you change a parameter, the Undo the last action link is displayed and you can undo the latest change.
The Failover Live step is displayed. The topology shows the number of VPGs and virtual machines being failed over to each recovery site.
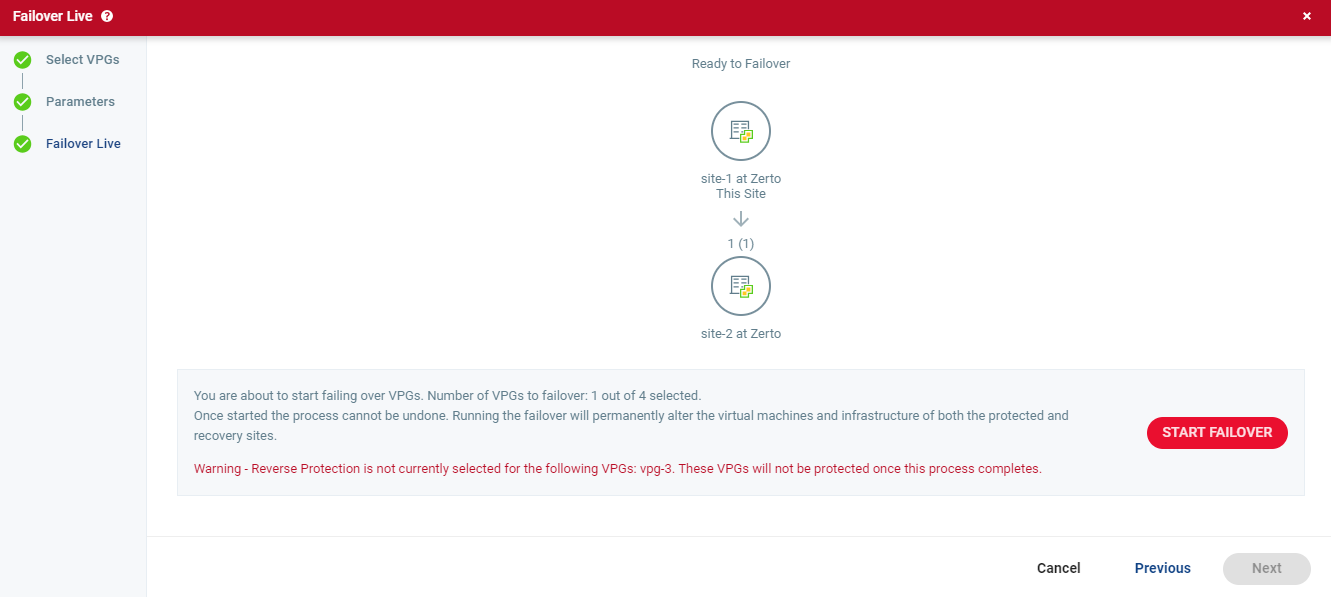
A warning message appears, presenting a summary of your Commit Policy.
| 6. | Review the Commit Policy summary, and either click Change Settings, or click START FAILOVER to start the failover. |
If a commit policy was set with a timeout greater than zero, you can check the failed over virtual machines on the recovery site before committing the failover operation.
The failover starts by creating the virtual machines in the recovery site to the point-in-time specified: either the last data transferred from the protected site or to one of the checkpoints written in the journal.
| Note: | If a virtual machine exists on the recovery site with the same name as a virtual machine being failed over, the machine is created and named in the peer site with a number added as a suffix to the name, starting with the number 1. |
If the original protected site is still up and reverse protection is configured to use the protected virtual machines virtual disks, these virtual machines are powered off.
The status icon changes to orange and an alert is issued, to warn you that the procedure is waiting for either a commit or rollback.
All testing done during this period, before committing or rolling back the failover operation, is written to thin-provisioned scratch virtual disks. These virtual disks are automatically defined when the machines are created on the recovery site for testing. The longer the test period the more scratch volumes are used, until the maximum size is reached, at which point no more testing can be done. The maximum size of all the scratch volumes is determined by the journal size hard limit and cannot be changed. The scratch volumes reside on the same datastore defined for the journal. Using these scratch volumes makes committing or rolling back the failover operation more efficient.
| Note: | You should not take a snapshot of a virtual machine before the failover operation is committed and the data from the journal promoted to the moved virtual machine disks, since the virtual machine volumes are still managed by the VRA and not directly by the virtual machine. Using a snapshot of a recovered machine before the failover operation has completed will result in a corrupted virtual machine being created. |
| 7. | Check the virtual machines on the recovery site, then either: |
| • | Wait for the specified Commit Policy time to elapse, and the specified operation, either Commit or Rollback, is performed automatically. |
| • | Or, in the specific VPG tab, click the Commit or Rollback icon ( ). ). |
| a. | If you clicked the Commit icon, the Commit window is displayed to confirm the commit and, if necessary set, or reset, the reverse protection configuration. |
| • | If the protected site is still up and you can set up reverse protection, you can reconfigure reverse protection by selecting the Reverse Protection checkbox and then click the Reverse link. |
| • | Configuring reverse protection at this point overwrites any of settings defined when initially configuring the move. |
| • | If specific VMs in a VPG are selected, a new VPG will be created in addition to the original VPG. The additional VPG includes only the VMs selected for recovery. The new VPG name is displayed as {Original-VPG-Name-Partial}. The original VPG will remain intact with its history. |
| b. | You can also commit or roll back the operation via the Tasks popup window in the status bar, or by selecting MONITORING > TASKS. |
If the original protected site is still up and reverse protection is configured to use the virtual disks of the protected virtual machines, these virtual machines are removed from this site, unless the original protected site does not have enough storage available to fail back the failed over virtual machines. Finally, data is promoted from the journal to the recovered virtual machines.
!Important:
| • | If Reverse Protection is selected and the virtual machines are already protected in other VPGs, the virtual machines or vCD vApp are deleted from the protected site and the journals of these VPGs are reset. |
This will result in the removal of these virtual machines from other VPGs that are protecting them, or the removal of the entire VPG, in the event of vCD vApp or if no other virtual machines are left to protect.
| • | If Reverse Protection is selected, and the virtual machines or vCD vApp are already protected in other VPGs, continuing with the operation will cause the other VPGs protecting the same virtual machines or vCD vApp to pause the protection. |
In the event of vCD vApp or if no other virtual machines are left to protect, the entire VPG will be removed. To resume the VPGs protection, you must edit the VPGs on the other sites and remove the virtual machine that was failed over from the protected site.
| Note: | Protecting virtual machines in several VPGs is enabled only if both the protected site and the recovery site, as well as the VRAs installed on these sites, are of version 5.0 and higher. |
During promotion of data, you cannot move a host on the recovered virtual machines. If the host is rebooted during promotion, make sure that the VRA on the host is running and communicating with the Zerto Virtual Manager before starting up the recovered virtual machines.
| Note: | If the virtual machines do not power on, the process continues and the virtual machines must be manually powered on. The virtual machines cannot be powered on automatically in a number of situations, such as when there is not enough resources in the resource pool or the required MAC address is part of a reserved range or there is a MAC address conflict or IP conflict, for example, if a clone was previously created with the MAC or IP address. |
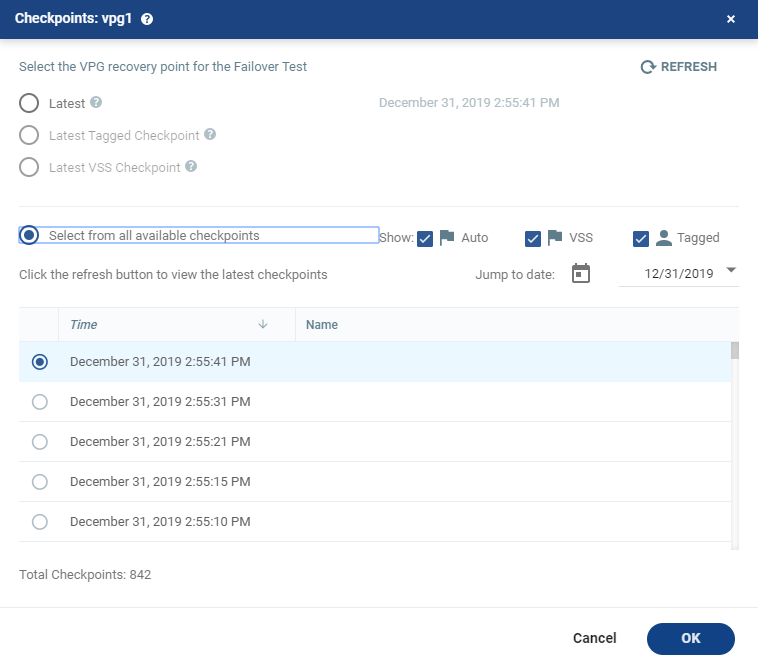
To select the checkpoint to use for the recovery:
| 1. | By default, the last checkpoint which was added to the journal is displayed in the Checkpoint column. |
| • | Either use this checkpoint, or select a different one. |
| • | To select a different checkpoint, click the checkpoint link. |
The Checkpoints window displays a list of the VPGs’ checkpoints.
RTip: The refresh button is initially grayed out and is enabled for clicking after 5 seconds. It is also grayed out for 5 seconds after being clicked, before being re-enabled.
| • | A reminder, Click the refresh button to view the latest checkpoints is displayed 10 seconds after the refresh button is clicked to remind the user that there is a new Latest Checkpoint. |
| • | If the user has scrolled to, and selected, a checkpoint anywhere in the checkpoints list, clicking the refresh button will automatically return the user to the selected checkpoint in the list. |
| 2. | Filter the list of checkpoints using the following options: |
| • | Latest: Recovery is to the latest checkpoint. This ensures that the data is crash-consistent for the recovery. |
When selecting the latest checkpoint, the checkpoint used is the latest at this point in time.
If a checkpoint is added between this point and starting the failover, this later checkpoint is not used.
| • | Latest Tagged Checkpoint: The recovery operation is to the latest checkpoint added in one of the following situations: |
| • | When a failover test was previously performed on the VPG that includes the virtual machine. |
| • | When the virtual machine was added to an existing VPG after the added virtual machine was synchronized. |
| • | Latest VSS Checkpoint: When VSS is used, the clone is to the latest VSS snapshot, ensuring that the data is both crash-consistent and application consistent to this point. |
The frequency of VSS snapshots determines how much data can be recovered. For details about VSS checkpoints, see VSS - Deployment and User Guide, in the section Ensuring Application Consistency – Adding Checkpoints.
| • | Select from all available checkpoints: Displays a complete list of all available checkpoints, including all the latest. |
By default, this option displays all checkpoints in the system. You can display Auto, VSS or Tagged checkpoints, or any combination of these.
| 3. | Select the checkpoint, then click OK. If the selected VMs were not protected when the selected checkpoint was taken, a warning will appear informing the user that these VMs cannot be recovered. If none of the selected VMs cannot be recovered, an error is displayed. |
To change the commit policy:
| 1. | Click the field or select the VPG and click EDIT SELECTED. |
| a. | Select None if you do not want an automatic commit or rollback. You must manually commit or roll back. |
If some VMs in a VPG fail to recover properly and Auto-Commit was selected for the operation, the commit policy will change to None. You must manually commit or rollback.
| b. | To test before committing or rolling back, specify an amount of time to test the recovered machines, in minutes. |
This is the amount of time that the commit or rollback operation is delayed, before the automatic commit or rollback action is performed.
During this time period, check that the new virtual machines are OK and then commit the operation or roll it back.
The maximum amount of time you can delay the commit or rollback operation is 1440 minutes, which is 24 hours.
Testing that involves I/O is done on scratch volumes.
| • | The more I/Os generated, the more scratch volumes are used, until the maximum size is reached, at which point no more testing can be done. |
| • | The maximum size of all the scratch volumes is determined by the journal size hard limit and cannot be changed. |
| • | The scratch volumes reside on the storage defined for the journal. |
To specify the shutdown policy:
Click the VM Shutdown field and select the shutdown policy:
| • | No (default): The protected virtual machines are not touched before starting the failover. This assumes that you do not know the state of the protected machines, or you know that they are not serviceable. |
| • | Yes: If the protected virtual machines have have a utility such as VMware Tools or Microsoft Integration Services available, the virtual machines are gracefully shut down, otherwise the Failover operation fails. This is similar to performing a Move operation to a specified checkpoint. |
| • | Force Shutdown: The protected virtual machines are forcibly shut down before starting the failover. This is similar to performing a Move operation to a specified checkpoint. If the protected virtual machines have have VMware Tools or Microsoft Integration Services available, the procedure waits five minutes for the virtual machines to be gracefully shut down before forcibly powering them off. |
To specify reverse protection:
When using reverse protection, virtual machines in the VPG are failed over to the recovery site and then protected in the recovery site, back to the original site.
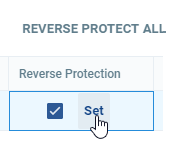
| • | Click REVERSE PROTECT ALL. This activates reverse protection on all the VPGs and/or VMs. The system default values for this procedure will be assigned to all the VPGs. |
- Or -
| • | Select the Reverse Protection checkbox to enable reverse protection and click Set next to the selected checkbox to set the reverse protection parameters. |
The Edit Reverse VPG wizard is displayed.
When committing the failover, you can reconfigure reverse protection, regardless of the reverse protection settings specified here. For more information, see Reverse Protection For a Moved VPG .
The protected virtual machines are created as new instances in EC2. The default value for new instances in Zerto is m5.xlarge. If these instances do not meet your needs, you can change this value in the Policies tab of the Site Settings dialog, see Configuring Disaster Recovery Policies. You can also change the instance type of new instances when you create or edit a VPG.
If you did not define a private IP for a virtual machine in the VPG definition, during recovery AWS sets the private IP from the defined subnet range.
See also: