Hive 설정¶
Driverless AI를 통해 Driverless AI 애플리케이션 내에서 Hive 데이터 소스를 탐색할 수 있습니다. 이 섹션에서는 Hive와 함께 작동할 수 있도록 Driverless AI를 구성하기 위한 지침을 제공합니다.
Note: Docker 설치 버전에 따라, Driverless AI Docker 이미지를 시작할 때는 docker run --runtime=nvidia (Docker 19.03 이후) 또는 nvidia-docker (Docker 19.03 이전) 명령을 사용하십시오. 사용 중인 Docker 버전을 확인하려면 docker version 을 사용하십시오.
구성 속성에 관한 설명¶
enabled_file_systems: 활성화할 파일 시스템. 데이터 커넥터를 제대로 작동시키려면 이 시스템을 구성해야 합니다.hive_app_configs: Hive 커넥터 구성. 입력은 HDFS 커넥터 구성과 비슷합니다. 중요한 키는 아래와 같습니다.hive_conf_path: Hive 구성 경로. 이것은 여러 파일(예: hive-site.xml, hdfs-site.xml 등)을 포함할 수 있습니다.auth_type: Keberos 인증을 위해noauth,keytab, 또는keytabimpersonation중 하나를 지정합니다.keytab_path: 인증에 사용할 Kerberos 키 탭의 경로를 지정하십시오(auth_type='noauth'를 사용하는 경우 《》일 수도 있습니다).principal_user: Kerberos 앱의 주 사용자를 지정하십시오(auth_type='keytab'또는auth_type='keytabimpersonation사용시 필요함).
해당 구성은 다중 키를 포함한 JSON/Dictionary 문자열이어야 합니다. 예를 들면 다음과 같습니다.
"""{ "hive_connection_1": { "hive_conf_path": "/path/to/hive/conf", "auth_type": "one of ['noauth', 'keytab', 'keytabimpersonation']", "keytab_path": "/path/to/<filename>.keytab", "principal_user": "hive/LOCALHOST@H2O.AI", }, "hive_connection_2": { "hive_conf_path": "/path/to/hive/conf_2", "auth_type": "one of ['noauth', 'keytab', 'keytabimpersonation']", "keytab_path": "/path/to/<filename_2>.keytab", "principal_user": "my_user/LOCALHOST@H2O.AI", } }"""Note:
hive_app_configs의 예상 입력값은 JSON string. 입니다. 큰따옴표("...")는 JSON dictionary within*에 키와 값을 나타내는 데 사용해야 하며, *outer 따옴표는""",''', 또는'형식으로 지정해야 합니다. 구성 값의 적용 방식에 따라 다른 형식의 외부 인용이 필요할 수 있습니다. 다음 예제는 외부 인용문을 적용하는 두 가지 독특한 방법을 보여줍니다.
config.toml 파일에 적용된 구성값:
hive_app_configs = """{"my_json_string": "value", "json_key_2": "value2"}"""
환경 변수로 적용된 구성 값:
DRIVERLESS_AI_HIVE_APP_CONFIGS='{"my_json_string": "value", "json_key_2": "value2"}'
hive_app_jvm_args: JAAS 필요 시, Hive 커넥터에 대한 추가 JVM(Java 가상 머신) 인수를 지정하십시오. 각각의 인수는 공백으로 구분되어야 합니다. 아래는 이 config.toml 옵션의 지정 방법의 예입니다.
hive_app_jvm_args = "-Xmx20g -Djavax.security.auth.useSubjectCredsOnly=false -Djava.security.auth.login.config=/etc/dai/jaas.conf"Notes:
Kerberos 인증 및 가장에는
-Djavax.security.auth.useSubjectCredsOnly=false기본 arg가 필요합니다.
-Djava.security.auth.login.config = / etc / dai / jaas.conf기본 arg는 기본 커넥터 프로세스가 /etc/dai/jaas.conf에 정의된 Kerberos 로그인 속성의 사용을 허용하는 데 필요합니다. jaas.conf 파일을 작성하여 지정된 디렉터리에 배치하십시오. 아래는 jaas.conf 파일 지정 방법에 대한 예제입니다.com.sun.security.jgss.initiate { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true useTicketCache=false principal="super-qa/mr-0xg9.0xdata.loc@H2OAI.LOC" [Replace this line] doNotPrompt=true keyTab="/etc/dai/super-qa.keytab" [Replace this line] debug=true; };
인증을 통한 Hive 활성화¶
본 섹션에서는 Docker에서 Driverless AI의 시작 시, Hive의 활성화 방법에 관해 설명합니다. 이것은 nvidia-docker run 명령에서 각각의 환경 변수를 지정하거나 또는 config.toml 파일에서 구성 옵션을 수정한 후, nvidia-docker run 명령에서 해당 파일을 지정하여 수행이 가능합니다.
Driverless AI Docker 이미지를 시작합니다.
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,hdfs,hive" \ -e DRIVERLESS_AI_HIVE_APP_CONFIGS='{"hive_connection_2: {"hive_conf_path":"/etc/hadoop/conf", "auth_type":"keytabimpersonation", "keytab_path":"/etc/dai/steam.keytab", "principal_user":"steam/mr-0xg9.0xdata.loc@H2OAI.LOC"}}' \ -p 12345:12345 \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -v /path/to/hive/conf:/path/to/hive/conf/in/docker \ -v /path/to/hive.keytab:/path/in/docker/hive.keytab \ -u $(id -u):${id -g) \ h2oai/dai-centos7-x86_64:1.9.2.1-cuda10.0.xx
이 예제에서는 config.toml 파일에서 Hive 옵션을 구성하는 방법과 Docker에서 Driverless AI의 시작 시 해당 파일을 지정하는 방법을 보여줍니다.
Driverless AI config.toml 파일에서 Hive 커넥터를 활성화 및 구성하십시오. Hiive 커넥터 구성은 다중 키를 포함한 JSON/Dictionary 문자열이어야 합니다.
enabled_file_systems = "file, hdfs, s3, hive" hive_app_configs = """{"hive_1": {"auth_type": "keytab", "key_tab_path": "/path/to/Downloads/hive.keytab", "hive_conf_path": "/path/to/Downloads/hive-resources", "principal_user": "hive/localhost@H2O.AI"}}"""
config.toml 파일을 Docker 컨테이너에 마운트하십시오.
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro / -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -v /path/to/hive/conf:/path/to/hive/conf/in/docker \ -v /path/to/hive.keytab:/path/in/docker/hive.keytab \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:1.9.2.1-cuda10.0.xx
이를 통해 Hive 커넥터를 활성화할 수 있습니다.
Driverless AI config.toml file을 내보거나 ~/.bashrc에 추가합니다.
# DEB and RPM export DRIVERLESS_AI_CONFIG_FILE="/etc/dai/config.toml" # TAR SH export DRIVERLESS_AI_CONFIG_FILE="/path/to/your/unpacked/dai/directory/config.toml"
config.toml 파일에서 아래 구성 옵션을 지정하십시오.
# File System Support # upload : standard upload feature # file : local file system/server file system # hdfs : Hadoop file system, remember to configure the HDFS config folder path and keytab below # dtap : Blue Data Tap file system, remember to configure the DTap section below # s3 : Amazon S3, optionally configure secret and access key below # gcs : Google Cloud Storage, remember to configure gcs_path_to_service_account_json below # gbq : Google Big Query, remember to configure gcs_path_to_service_account_json below # minio : Minio Cloud Storage, remember to configure secret and access key below # snow : Snowflake Data Warehouse, remember to configure Snowflake credentials below (account name, username, password) # kdb : KDB+ Time Series Database, remember to configure KDB credentials below (hostname and port, optionally: username, password, classpath, and jvm_args) # azrbs : Azure Blob Storage, remember to configure Azure credentials below (account name, account key) # jdbc: JDBC Connector, remember to configure JDBC below. (jdbc_app_configs) # hive: Hive Connector, remember to configure Hive below. (hive_app_configs) # recipe_url: load custom recipe from URL # recipe_file: load custom recipe from local file system enabled_file_systems = "file, hdfs, s3, hive" # Configuration for Hive Connector # Note that inputs are similar to configuring HDFS connectivity # Important keys: # * hive_conf_path - path to hive configuration, may have multiple files. Typically: hive-site.xml, hdfs-site.xml, etc # * auth_type - one of `noauth`, `keytab`, `keytabimpersonation` for kerberos authentication # * keytab_path - path to the kerberos keytab to use for authentication, can be "" if using `noauth` auth_type # * principal_user = Kerberos app principal user. Required when using auth_type `keytab` or `keytabimpersonation` # JSON/Dictionary String with multiple keys. Example: # """{ # "hive_connection_1": { # "hive_conf_path": "/path/to/hive/conf", # "auth_type": "one of ['noauth', 'keytab', 'keytabimpersonation']", # "keytab_path": "/path/to/<filename>.keytab", # principal_user": "hive/LOCALHOST@H2O.AI", # } # }""" # hive_app_configs = """{"hive_1": {"auth_type": "keytab", "key_tab_path": "/path/to/Downloads/hive.keytab", "hive_conf_path": "/path/to/Downloads/hive-resources", "principal_user": "hive/localhost@H2O.AI"}}"""
완료되면 변경 사항을 저장하고 Driverless AI를 중지/재시작하십시오.
Hive를 사용하여 데이터 세트 추가¶
Hive 커넥터가 활성화된 후, Add Dataset (or Drag and Drop) 드롭다운 메뉴에서 Hive 를 선택하여 데이터 세트를 추가할 수 있습니다.
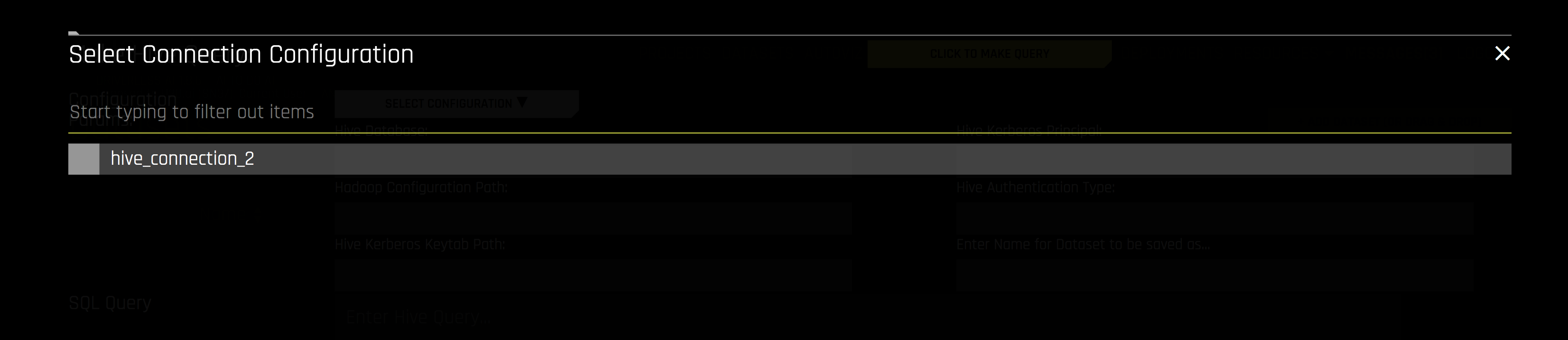
사용할 Hive 구성을 선택하십시오.
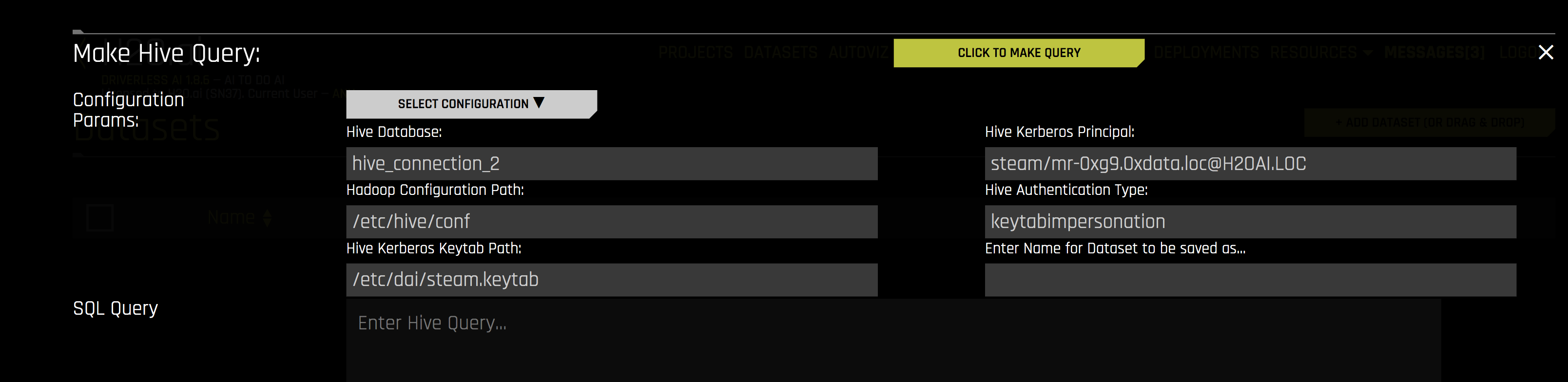
데이터 세트를 추가하려면 다음 정보를 지정하십시오.
Hive Database: 쿼리 중인 Hive 데이터베이스의 명칭을 지정하십시오.
Hadoop Configuration Path: Hive 구성 파일의 경로를 지정하십시오.
Hive Kerberos Keytab Path: Hive Kerberos 키 탭의 경로를 지정하십시오.
Hive Kerberos Principal: Hive Kerberos 주체를 지정하십시오. 이것은 Hive 인증 유형이 keytabimpersonation인 경우에 필요합니다.
Hive Authentication Type: 인증 유형을 지정하십시오. 이는 noauth, keytab 또는 keytabimpersonation일 수도 있습니다.
Enter Name for Dataset to be saved as: 업로드 중인 데이터 세트의 새 이름을 선택적으로 지정하십시오.
SQL Query: 실행할 Hive 쿼리를 지정하십시오.