Policies Dialog
You can set default recovery and replication policies.
To configure disaster recovery policies:
|
•
|
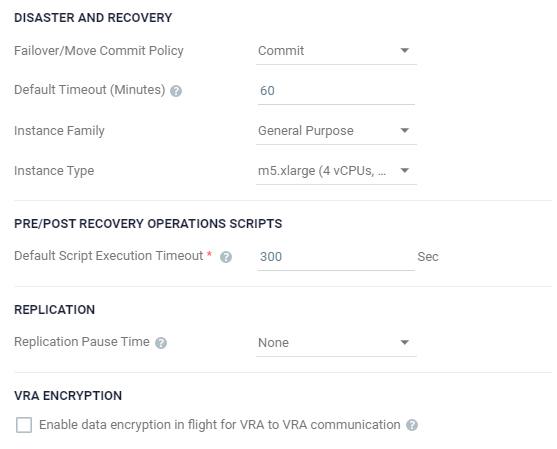
None: The failover or move operation must be manually committed or rolled back by the user. |
|
•
|
Commit: After the time specified in the Default Timeout field the failover or move operation is committed, unless manually committed or rolled back by the user before the time-out value is reached. During the specified time you can check the recovered VPG virtual machines. |
|
•
|
Rollback: After the time specified in the Default Timeout field the failover or move operation is rolled back, unless manually committed or rolled back by the user before the time-out value is reached. During the specified time you can check the recovered VPG virtual machines. |
The value set here applies as the default for all failover or move operations from this point on but can be changed when defining a failover or move operation.
|
3.
|
Specify the Default Timeout after which a Commit or Rollback commit policy is performed. A value of zero indicates that the system will automatically perform the commit policy, without waiting for any user interaction. |
|
4.
|
Choose the Instance Family from which to select the type. AWS instance families are optimized for different types of applications. |
|
5.
|
Choose the Instance Type within the instance family, to assign to recovered instances. Different types within an instance family vary primarily in vCPU, ECU, RAM, and local storage size. The price per instance is directly related to the instance size. |
|
6.
|
Specify the Default Script Execution Timeout or a script running before or after the failover, move, or test failover. A value of zero indicates that there is no time out. Values can be between 300 to 6000 seconds. |
|
7.
|
Choose the Replication Pause Time, which is the time to pause when the journal might have problems, resulting in the loss of all checkpoints, for example, when the datastore for the journal is near to being full. |
The replication pause time is the amount of time that the transfer of data from the protected site to the journal on the recovery site is paused. This time can then be used by the administrator to resolve the issue, for example by cloning the virtual machines in the VPG, described in Cloning Protected Virtual Machines to the Remote Site. The value set here is applied to existing and new VPGs.
|
8.
|
In the VRA Encryption area, to secure the communication channel between the VRA and its peer VRAs, select Enable data encryption in flight for VRA to VRA communication. |
By enabling VRA encryption, the VRA to VRA communication channel will be made secure and encrypted (TLS over TCP), and will be carried out over two new ports: 9007 and 9008.
|
Note:
|
VRA to VRA Encryption is not intended to replace a VPN or any private connection. |
Considerations:
|
•
|
To avoid site disconnections, make sure ports 9007 and 9008 are open for communication between your peer VRAs. |
|
•
|
For encryption between cross site peer VRAs, enable VRA encryption on both sites. |
|
•
|
VRA encryption requires that your Hosts' CPU supports AES_NI. |
|
•
|
After enabling encryption, you may experience some degradation in replication performance due to CPU consumption. |
This is only likely to be noticed:
|
•
|
During a large Initial Sync between the sites. |
|
•
|
In environments where the Network and Storage support large throughputs, where the CPU might become a bottleneck. |
|
•
|
Enabling encryption might also affect your VRAs compression ratio. |
|
•
|
To reduce the encryption impact on performance, Zerto recommends you add a second vCPU to each VRA. |
!
Important:
|
•
|
Increasing the number of vCPUs to two is recommended if the VRA is used for Long-term Retention, or for high loads. |
|
•
|
Increasing the number of vCPUs to more than two should only be per Zerto Support recommendation. |
See also: