

[ Guide contents | Next chapter: 2 Overview ]
[ Guide contents | Next chapter: 2 Overview ]
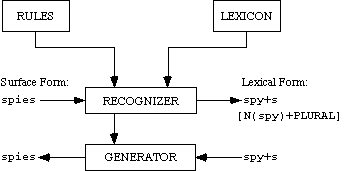
Figure 1.1 Main components of Karttunen's KIMMO parser
Figure 1.2 Parse tree and feature structure for enlargements
Figure 1.3 Fragment of a word grammar of English
This chapter describes PC-KIMMO, a morphological parser based on Kimmo Koskenniemi's model of two-level morphology ( Koskenniemi 1983). While PC-KIMMO was adequate to decompose a word into morphemes, it was not able directly to compute the part of speech of a derivationally complex word or return a word's inflectional features--precisely the information required for syntactic parsing. These deficiencies have now been remedied by adding a unification-based word grammar component to version 2 of PC-KIMMO which can provide parse trees and feature structures. A substantial analysis of English for use with PC-KIMMO is also described.
Even for English a morphological parser may be necessary. Although English has a limited inflectional system, it has very complex and productive derivational morphology. For example, from the root compute come derived forms such as computer, computerize, computerization, recomputerize, noncomputerized, and so on. It is impossible to list exhaustively in a lexicon all the derived forms (including coined terms or inventive uses of language) that might occur in natural text.
Lexical form: c h a s e + e d Surface form: c h a s 0 0 e dFor more on the phonological properties of the two-level model, see Antworth 1991.
Figure 1.1 Main components of Karttunen's KIMMO parser
Form: en+ `large +ment +s
Gloss: VR1+ `large +NR25 +PL
Cat: PREFIX AJ SUFFIX INFL
Feat: [from_pos:AJ [head: [pos:AJ]] [from_pos:V [from_pos:N
head: [pos:V]] head: [pos:N]] head: [number:PL
pos: N ]]
This analysis is then passed to the word grammar, which returns the parse
tree and feature structure shown in Figure 1.2.
Figure 1.2 Parse tree and feature structure for enlargements
Word
______|_______
Stem INFL
_____|______ +s
Stem SUFFIX +PL
___|____ +ment
PREFIX Stem +NR25
en+ |
VR1+ ROOT
`large
`large
Word:
[ head: [ pos: N
number:PL ]]
While each node of the tree has a feature structure associated with it, the
feature structure for the top node is the most important, since these are
the features attributable to the entire word. The feature structure for the
word enlargements specifies two features. First, the feature
pos has the value N, meaning that the part-of-speech
(lexical category) of the word is Noun. Second, the feature number has
the value PL for plural. If PC-KIMMO were being called from a
syntactic parser, then it would return to the syntactic parser the word
enlargements with these features. In its overall architecture,
version 2 of PC-KIMMO now resembles the morphological parser described in
Ritchie and others 1992. That parser also first
tokenizes a word into morphemes and then parses the morpheme sequence with
a unification-based parser. However, our unification parser differs
considerably from theirs in its implementation.
The word grammar component uses a grammar file written by the user. A grammar consists of context-free rules and feature constraints. The format of the grammar closely follows Shieber's PATR-II formalism ( Shieber 1986). Figure 1.3 shows a fragment of a word grammar of English.
Figure 1.3 Fragment of a word grammar of English
;FEATURE ABBREVIATIONS:
Let pl be <head number> = PL
LET v/n be <from_pos> = V
<head pos> = N
<head number> = !SG
LET v\aj be <from_pos> = AJ
<head pos> = V
;CATEGORY TEMPLATES:
Let N be <cat> = ROOT
<head pos> = N
<head number> = !SG
Let V be <cat> = ROOT
<head pos> = V
Let AJ be <cat> = ROOT
<head pos> = AJ
;Rule 1
Word = Stem INFL
<Stem head pos> = <INFL from_pos>
<Word head> = <INFL head>
;Rule 2
Stem_1 = PREFIX Stem_2
<PREFIX from_pos> = <Stem_2 head pos>
<Stem_1 head> = <PREFIX head>
;Rule 3
Stem_1 = Stem_2 SUFFIX
<Stem_2 head pos> = <SUFFIX from_pos>
<Stem_1 head> = <SUFFIX head>
;Rule 4
Stem = ROOT
<Stem head> = <ROOT head>
The first section of the
grammar file contains feature abbreviations. Feature abbreviations can
be used either in lexical entries or in grammar rules and are expanded
by "LET" statements. For example, the feature abbreviation pl is
expanded into the feature structure [head: [number: PL]].
The second section of the grammar file contains category templates. These are feature specifications that are attached to lexical categories such as Noun and Adjective. This greatly reduces the amount of information that must be stored in the lexicon. For example, the statement Let N be <head number> = SG means that all nouns are assigned singular number. The grammar in Figure 1.3 actually contains the statement Let N be <head number> = !SG. The exclamation point in !SG means that this is a default value which can be overridden. For example, the lexical entry for fox does not need to specify that it is singular; that information is supplied by the category definition of Noun. However, the lexical entry for mice (an irregular plural) explicitly sets the feature number feature to PL (plural), thus overriding the default value.
The third section of the grammar file contains the word grammar rules. Associated with each rule are feature constraints. A feature constraint consists of two feature structures which must unify with each other. Feature constraints have two functions: they constrain the operation of a rule and they pass features from one node to another up the parse tree. For example, in rule 1 of Figure 1.3 the feature constraint <Stem head pos> = <INFL from_pos> requires that the pos feature of the Stem node must have the same value as the from_pos feature of the INFL node in order for the rule to succeed, while the feature constraint <Word head> = <INFL head> passes the values of the head features (including pos) from the INFL node to the head features of the Word node.
The word enlargements is an especially good example of the power of the word grammar because of its complex derivational structure. Its root is the adjective large; the prefix en- forms the verb enlarge; the suffix -ment forms the noun enlargement; and finally the inflectional suffix s marks it plural. To accomplish this, each root or stem has a lexical category such as Noun or Adjective and each affix has a from_pos feature and a pos feature. The from_pos feature specifies the lexical category of the stems to which it can attach. The pos feature specifies the lexical category of the resulting stem. For instance, the prefix en- has a from_pos of Adjective and a pos of Verb, since it attaches to an adjective such as large and produces a verb, enlarge. Rule 2 in Figure 1.3 says that a Stem is composed of a PREFIX plus a Stem, for instance enlarge = en+large. The first feature constraint, <PREFIX from_pos> = <Stem_2 head pos>, requires that the from_pos feature of the PREFIX node must have the same value as the pos feature of the Stem_2 node. Since the from_pos feature of the prefix en- and the pos feature of the stem large are both AJ, the rule succeeds. The second feature constraint, <Stem_1 head> = <PREFIX head>, passes the value of the <head pos> feature from the PREFIX node to the <head pos> feature of the Stem node; that is, since the <head pos> of the prefix en- is V, the <head pos> of the resulting stem enlarge is also V.
Rule 1 in Figure 1.3 accounts for the plural suffix -s. The rule simply says that a word is composed of a stem plus an inflectional element. The two feature constraints use the <head pos>, <from_pos>, and <pos> features to ensure that the plural suffix attaches only to a noun stem and produces a noun word (that is, it does not change the part of speech of the stem as do the derivational affixes).
In terms of its coverage of English, Englex has these goals:
North Texas Natural Language Processing Workshop
May 23, 1994
University of Texas at Arlington