Configuring an ML-AutoDoc¶
Rendering an ML-AutoDoc requires a running H2O Cluster, a trained model, and access to the datasets used to train the model.
This section includes the code examples for setting up a model, along with basic and advanced ML-AutoDoc configurations. To experiment with a complete end-to-end example, run the Building an H2O Model code example before running one of the ML-AutoDoc-specific examples.
Setup:
Basic configurations:
Advanced configurations:
Building an H2O Model¶
First, connect to your Steam-launched H2O-3 or Sparkling Water cluster.
import h2o
from h2o.estimators.gbm import H2OGradientBoostingEstimator
# import datasets for training and validation
train_path = "https://s3.amazonaws.com/h2o-training/events/ibm_index/CreditCard_Cat-train.csv"
valid_path ="https://s3.amazonaws.com/h2o-training/events/ibm_index/CreditCard_Cat-test.csv"
# import the train and valid dataset
train = h2o.import_file(train_path, destination_frame='CreditCard_Cat-train.csv')
valid = h2o.import_file(valid_path, destination_frame='CreditCard_Cat-test.csv')
# set predictors and response
predictors = train.columns
predictors.remove('ID')
response = "DEFAULT_PAYMENT_NEXT_MONTH"
# convert target to factor
train[response] = train[response].asfactor()
valid[response] = valid[response].asfactor()
# assign IDs for later use
h2o.assign(train, "CreditCard_TRAIN")
h2o.assign(valid, "CreditCard_VALID")
# build an H2O-3 GBM Model
gbm = H2OGradientBoostingEstimator(model_id="gbm_model", seed=1234)
gbm.train(x = predictors, y = response, training_frame = train, validation_frame = valid)
from pysparkling import *
hc = H2OContext.getOrCreate(spark)
# import h2o
import h2o
from h2o.estimators.gbm import H2OGradientBoostingEstimator
# import datasets for training and validation
train_path = "https://s3.amazonaws.com/h2o-training/events/ibm_index/CreditCard_Cat-train.csv"
valid_path ="https://s3.amazonaws.com/h2o-training/events/ibm_index/CreditCard_Cat-test.csv"
# import the train and valid dataset
train = h2o.import_file(train_path, destination_frame='CreditCard_Cat-train.csv')
valid = h2o.import_file(valid_path, destination_frame='CreditCard_Cat-test.csv')
# set predictors and response
predictors = train.columns
predictors.remove('ID')
response = "DEFAULT_PAYMENT_NEXT_MONTH"
# convert target to factor
train[response] = train[response].asfactor()
valid[response] = valid[response].asfactor()
# assign IDs for later use
h2o.assign(train, "CreditCard_TRAIN")
h2o.assign(valid, "CreditCard_VALID")
# build an H2O-3 GBM Model
gbm = H2OGradientBoostingEstimator(model_id="gbm_model", seed=1234)
gbm.train(x = predictors, y = response, training_frame = train, validation_frame = valid)
Generate a Default ML-AutoDoc¶
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# use default configuration settings
config = AutoDocConfig()
# specify the path to the output file
output_file_path = "autodoc_report.docx"
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Set the ML-AutoDoc Report Name¶
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# use default configuration settings
config = AutoDocConfig()
# specify the path to the output file
output_file_path = "my_H2O3_autoreport.docx"
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Set the ML-AutoDoc File Type¶
The ML-AutoDoc can generate a Word document or markdown file. The default report is a Word document (e.g., docx).
Word Document
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# use default configuration settings
config = AutoDocConfig()
# specify the path to the output file
output_file_path = "my_word_report.docx"
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Markdown File
Note when the main_template_type is set to “md” a zip file is returned. This zip file contains the markdown file and any images that are linked in the markdown file.
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# specify the path to the output file
output_file_path = "my_markdown_report.md"
# set the exported report to markdown ('md')
main_template_type = "md"
config = AutoDocConfig(main_template_type=main_template_type)
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Model Interpretation Dataset¶
The ML-AutoDoc report can include partial dependence plots (PDPs) and Shapley value feature importance. By default, these calculations are done on the training frame. You can use the mli_frame (short for machine learning interpretability dataframe) AutoDocConfig parameter to specify a different dataset on which to perform these calculations. In the example below, we will specify that the machine learning interpretability (MLI) calculations are done on our model’s validation dataset, instead of the training dataset.
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# specify the path to the output file
output_file_path = "my_mli_report.docx"
# specify the H2OFrame on which the partial dependence and Shapley values can be calculated
# here 'valid' was created in the Build H2O Model code example
mli_frame = valid
config = AutoDocConfig(mli_frame=mli_frame)
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Partial Dependence Features¶
The ML-AutoDoc report includes partial dependence plots (PDPs). By default, PDPs are shown for the top 20 features. This selection is based the model’s built-in variable importance (referred to as Native Importance in the report). You can override the default behavior with the pdp_feature_list parameter, and specify your own list of features to show in the report.
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# specify the path to the output file
output_file_path = "my_pdp_report.docx"
# specify the features you want PDP plots
# here the feature came from predictors used in the Build H2O Model code example.
pdp_feature_list = ["EDUCATION", "LIMIT_BAL", "AGE"]
config = AutoDocConfig(pdp_feature_list=pdp_feature_list)
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Specify ICE Records¶
The ML-AutoDoc can overlay partial dependence plots with individual conditional expectation (ICE) plots. You can specify which observations (aka rows) you’d like to plot (manual selection), or you can let ML-AutoDoc automatically select observations.
Manual Selection
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# specify the path to the output file
output_file_path = "my_manual_ice_report.docx"
# specify an H2OFrame composed of the records you want shown in the ICE plots
# here 'valid' was created in the Build H2O Model code example - we use the first 2 rows.
ice_frame = valid[:2, :]
config = AutoDocConfig(ice_frame=ice_frame)
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Automatic Selection
The num_ice_rows AutoDocConfig parameter controls the number of observations selected for an ICE plot. This feature is disabled by default (i.e., set to 0). Observations are selected by binning the predictions into N quantiles and selecting the first observation in each quantile.
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# specify the path to the output file
output_file_path = "my_auto_ice_report.docx"
# specify the number of rows you want automatically selected for ICE plots
num_ice_rows = 3
config = AutoDocConfig(num_ice_rows=num_ice_rows)
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Enable Shapley Values¶
Shapley values are provided for supported H2O-3 Algorithms. (For supported algorithms, see the H2O-3 user guide.)
Note: Shapley values are disabled by default because they can take a long time to complete for wide datasets.
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# get H2O-3 objects required to create an automatic report
model = h2o.get_model("gbm_model")
train = h2o.get_frame("CreditCard_TRAIN")
# specify the path to the output file
output_file_path = "my_shapley_report.docx"
# enable shapley values
use_shapley = True
config = AutoDocConfig(use_shapley=use_shapley)
# download an ML-AutoDoc
cluster.download_autodoc(
model=model,
config=config,
train_frame=train,
path=output_file_path,
)
Provide Alternative Models¶
You can provide a list of alternative models to the render_autodoc() function. This will create model tuning tables with unique-valued hyperparameters for each alternative model.
Rendered Output
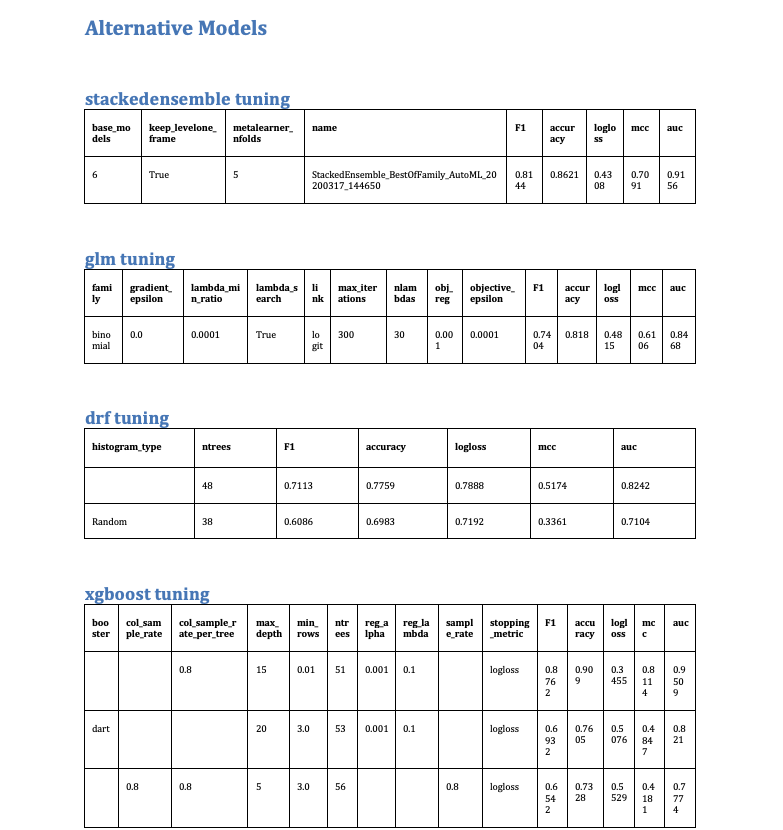
Code Example
import h2o
from h2o.automl import H2OAutoML
# import the titanic dataset from Amazon S3
titanic = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/"
"smalldata/gbm_test/titanic.csv",
destination_frame="titanic_all",
)
# specify the predictors and response
predictors = ["home.dest", "cabin", "embarked", "age"]
response = "survived"
titanic["survived"] = titanic["survived"].asfactor()
# split the titanic dataset into train, valid, and test
train, valid, test = titanic.split_frame(
ratios=[0.8, 0.1],
destination_frames=["titanic_train", "titanic_valid", "titanic_test"],
)
# run AutoML
automl = H2OAutoML(max_models=3, seed=1)
automl.train(
predictors, response, training_frame=train, validation_frame=valid,
)
board = automl.leaderboard.as_data_frame()
# build a report on the best performing model
best_model = automl.leader
# compare the best model to the other models in leaderboard
models = [h2o.get_model(x) for x in board["model_id"][1:]]
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# specify the path to the output file
output_file_path = "my_alternative_models_report.docx"
config = AutoDocConfig()
# render a report with your best model and alternative models
cluster.download_autodoc(
model=best_model,
config=config,
path=output_file_path,
train_frame=train,
valid_frame=valid,
test_frame=test,
alternative_models=models,
)
from pysparkling import *
import h2o
hc = H2OContext.getOrCreate(spark)
# import the titanic dataset from Amazon S3
titanic = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/"
"smalldata/gbm_test/titanic.csv",
destination_frame="titanic_all",
)
# specify the predictors and response
predictors = ["home.dest", "cabin", "embarked", "age"]
response = "survived"
titanic["survived"] = titanic["survived"].asfactor()
# split the titanic dataset into train, valid, and test
train, valid, test = titanic.split_frame(
ratios=[0.8, 0.1],
destination_frames=["titanic_train", "titanic_valid", "titanic_test"],
)
# run AutoML
automl = H2OAutoML(max_models=3, seed=1)
automl.train(
predictors, response, training_frame=train, validation_frame=valid,
)
board = automl.leaderboard.as_data_frame()
# build a report on the best performing model
best_model = automl.leader
# compare the best model to the other models in leaderboard
models = [h2o.get_model(x) for x in board["model_id"][1:]]
# import AutoDocConfig class
from h2osteam.utils import AutoDocConfig
# specify the path to the output file
output_file_path = "my_alternative_models_report.docx"
config = AutoDocConfig()
# render a report with your best model and alternative models
cluster.download_autodoc(
model=best_model,
config=config,
path=output_file_path,
train_frame=train,
valid_frame=valid,
test_frame=test,
alternative_models=models,
)