解释专家设置¶
以下为“解释”专家设置列表,这些设置可在从 MLI page 设置新建解释时使用。每项设置的名称前均带有其 config.toml 标签。
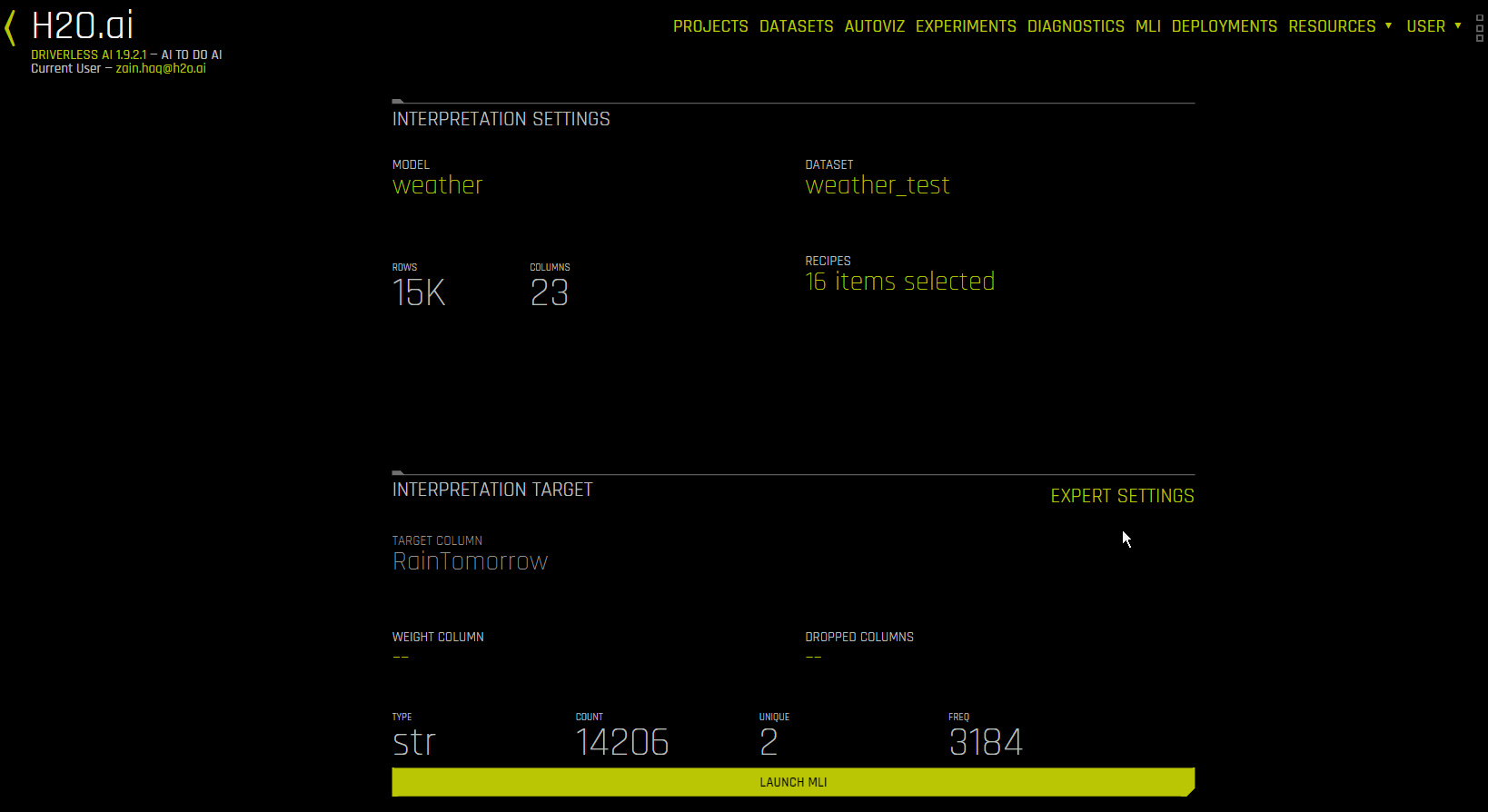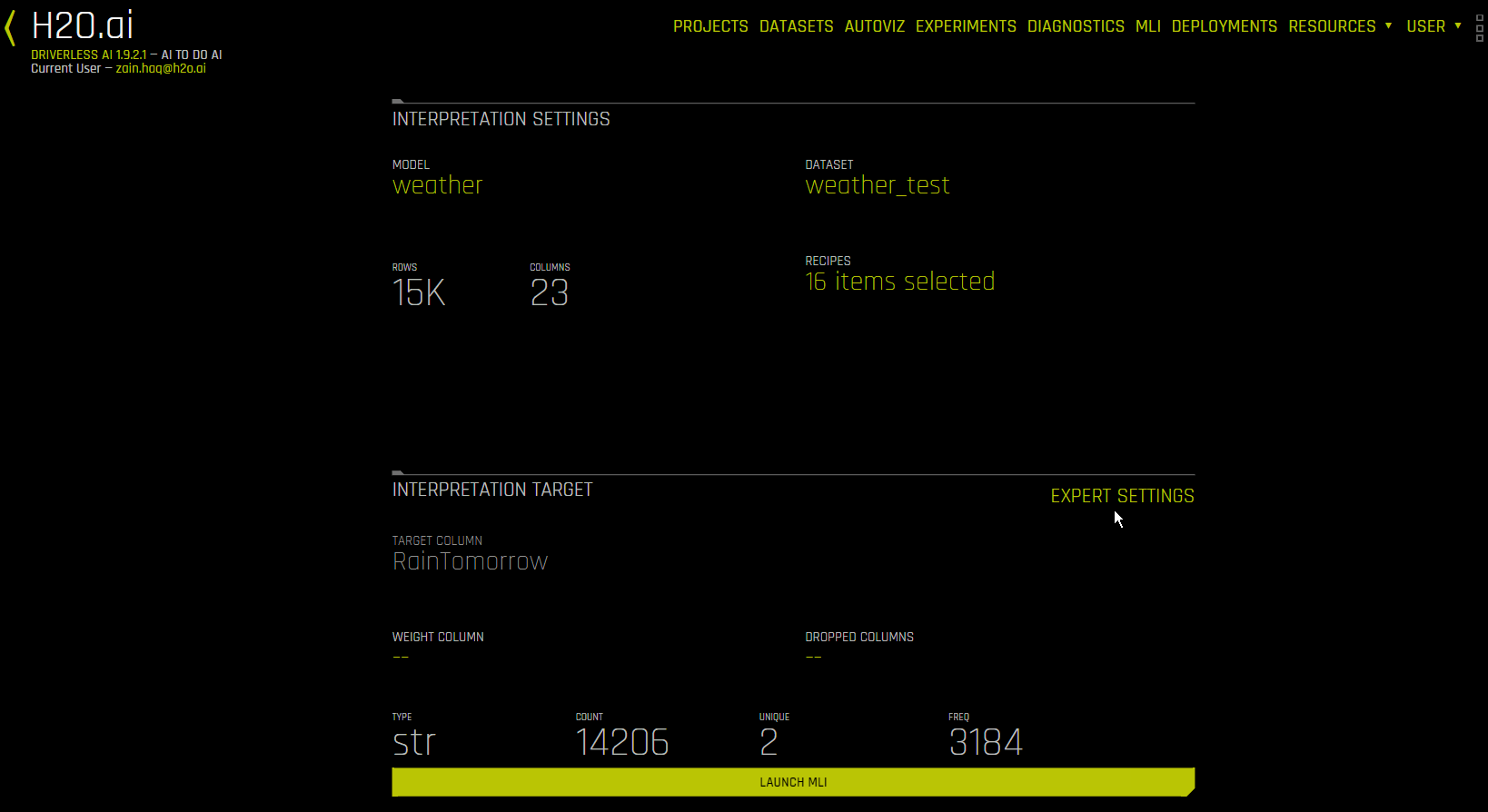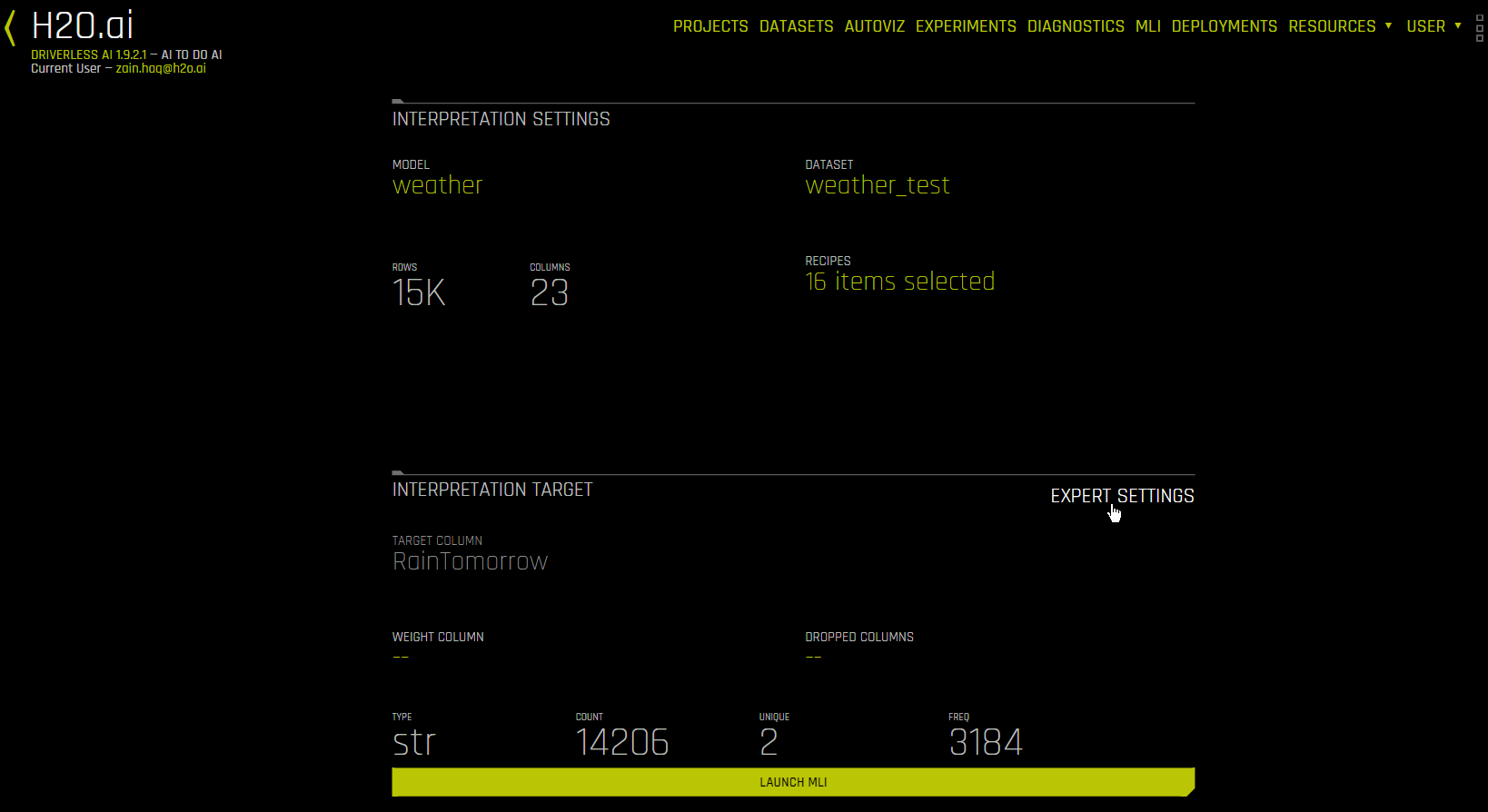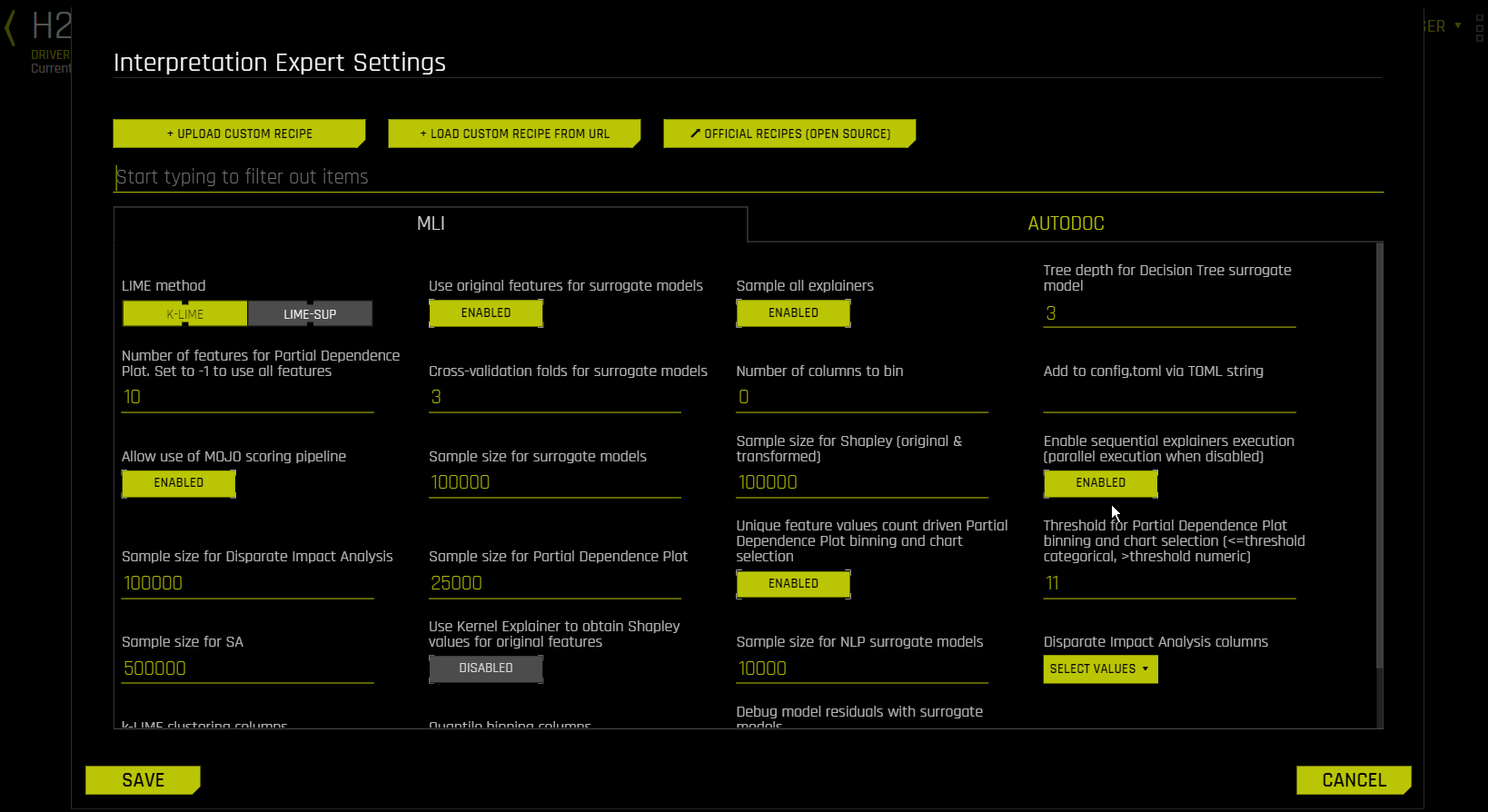
MLI 选项卡¶
mli_lime_method¶
LIME Method
选择 K-LIME(默认)或 LIME-SUP 作为 LIME 方法。
K-LIME (默认):使用所有训练数据创建全局替代 GLM 模型,并在由训练数据中的 k-means 聚类形成的样本上创建多个局部替代 GLM 模型。k-means 所使用的特征从 Random Forest 替代模型的变量重要性中选择。k-means 所使用的特征数量是 Random Forest 替代模型的变量重要性中前 25% 变量的最小值,以及可用于 k-means 的最大变量数量(由用户在 config.toml 设置中为
mli_max_number_cluster_vars设定)。(请注意,如果数据集中的特征数量小于或等于 6,则所有特征均被用于 k-means 聚类。)通过在 config.toml 文件中将use_all_columns_klime_kmeans设置为true,可关闭之前的设置,从而将所有特征用于 k-means。所有受到罚分的 GLM 替代模型均已经过训练,可对 Driverless AI 模型的预测结果进行建模。可通过网格搜索选择局部解释所使用的聚类数量,在搜索过程中,Driverless AI 模型预测结果和所有局部 K-LIME 模型预测结果之间的 \(R2\) 将被最大化。全局和局部线性模型的截距、系数、\(R2\) 值、准确度和预测结果均可用于调试和开发对 Driverless AI 模型性能的解释。LIME-SUP:从原始变量方面解释已训练的 Driverless AI 模型的局部区域。局部区域由决策树替代模型的每个叶节点路径决定,而不是由原始 LIME 中被模拟、被干扰的观测值样本决定。对于每个局部区域,使用原始输入数据和 Driverless AI 模型的预测结果训练局部 GLM 模型。随后,此局部 GLM 模型的参数可被用于生成 Driverless AI 模型的近似局部解释。
mli_use_raw_features¶
Use Original Features for Surrogate Models
指定在替代模型中是使用原始特征还是使用转换特征来执行新解释。默认会启用此项设置。
请注意:禁用此项设置后,K-LIME 聚类列和分位数分箱选项将无法使用。
mli_sample¶
Sample All Explainers
指定是否对训练数据样本执行解释。默认情况下,如果训练数据集大于 10 万行,则 MLI 将对其进行抽样。(等效的 config.toml 设置为 mli_sample_size. )默认会启用此项设置。关闭此切换开关即可对整个数据集运行 MLI。
mli_dt_tree_depth¶
Tree Depth for Decision Tree Surrogate Model
对于 KLIME 解释,指定您所需决策树替代模型的深度。树的深度值可以为 2 - 5 之间的值,默认值为 3。对于 LIME-SUP 解释,指定 LIME-SUP 树的深度。此值可以为 2 - 5 之间的值,默认值为 3。
mli_vars_to_pdp¶
Number of Features for Partial Dependence Plot
指定构建部分依赖性图时要使用的特征的最大数量。使用 -1 可计算所有特征的部分依赖性图。默认值为 10。
mli_nfolds¶
Cross-validation Folds for Surrogate Models
指定要使用的替代交叉验证折叠数量(0 到 10)。运行实验时,Driverless AI 会自动拆分训练数据并使用验证数据来确定模型参数调优和特征工程步骤的性能。对于新解释,Driverless AI 默认使用 3 个交叉验证折叠来进行解释。
mli_qbin_count¶
Number of Columns to Bin
指定要进行分箱的列数。默认值为 0。
mli_custom¶
Add to config.toml via TOML String
在此输入字段中填入 TOML 字符串以添加至 Driverless AI 服务器的 config.toml 配置文件中。
mli_enable_mojo_scorer¶
Allow Use of MOJO Scoring Pipeline
使用此选项可禁用 MOJO 评分管道。默认会自动选择评分管道(从 MOJO 和 Python 管道中选择)。对于某些模型,选择 MOJO 还是 Python 可能会影响管道的性能和可靠性。
mli_sample_size¶
Sample Size for Surrogate Models
当行数超出此限制时,将为替代模型进行抽样。默认值为 100000。
mli_shapley_sample_size¶
Sample Size for Shapley (Original & Transformed)
当行数超出此限制时,将为 MLI Shapley 计算进行抽样。默认值为 100000。
mli_sequential_task_execution¶
Enable Sequential Explainers Execution (Parallel Execution When Disabled)
指定是否启用解释器的顺序执行。默认会启用此项设置。禁用此设置时,将使用并行执行。
mli_dia_sample_size¶
Sample Size for Disparate Impact Analysis
当行数超出此限制时,将为差异影响分析 (DIA) 进行抽样。默认值为 100000。
mli_pd_sample_size¶
Sample Size for Partial Dependence Plot
当行数超出此限制时,将为 Driverless AI 部分依赖性图进行抽样。默认值为 25000。
mli_pd_numcat_num_chart¶
Unique Feature Values Count Driven Partial Dependence Plot Binning and Chart Selection
指定在实验将特征同时用作数值特征和分类特征的情况下,是否动态切换 PDP 数值和分类分箱与 UI 图表。默认会启用此项设置。
mli_pd_numcat_threshold¶
Threshold for PD/ICE Binning and Chart Selection
如果启用 mli_pd_numcat_num_chart ,且唯一特征值的数量大于阈值,则将使用数值分箱和图表。否则,将使用分类分箱和图表。默认阈值为 11。
mli_sa_sampling_limit¶
Sample Size for Sensitivity Analysis (SA)
当行数超出此限制时,将为敏感性分析 (SA) 进行抽样。默认值为 500000。
mli_nlp_sample_limit¶
Sample Size for NLP Surrogate Models
指定要执行 MLI NLP 的最大记录数量。默认值为 10000。
klime_cluster_col¶
k-LIME Clustering Columns
对于 k-LIME 解释,可指定要应用 k-LIME 聚类的列。
请注意:在 config.toml 文件中没有此项设置。
qbin_cols¶
Quantile Binning Columns
对于 k-LIME 解释,指定一列或多列以生成十分位数分箱(均匀分布),从而帮助提高 MLI 准确度。所选择的列会被添加至前 n 列中,用于选择分位数分箱。如果某个列不是数值列或不在数据集(转换特征)中,则将跳过此列。
请注意:在 config.toml 文件中没有此项设置。
AutoDoc 选项卡¶
autodoc_report_name¶
AutoDoc Name
指定 AutoDoc 的名称。
autodoc_template¶
AutoDoc Template Location
指定 AutoDoc 模板路径。提供自定义 AutoDoc 模板的完整路径。若需生成标准 AutoDoc,则将此字段保留为空白。
autodoc_output_type¶
AutoDoc File Output Type
指定 AutoDoc 文件输出类型。从 docx (默认值)和 md 中选择。
autodoc_subtemplate_type¶
AutoDoc Sub-Template Type
指定要使用的子模板类型。从以下类型中选择:
auto(默认)
md
docx
autodoc_max_cm_size¶
Confusion Matrix Max Number of Classes
指定混淆矩阵中的最大类别数。默认值为 10。
autodoc_num_features¶
Number of Top Features to Document
指定要在文档中显示的主要特征数量。若需禁用此设置,则指定 -1 。默认值为 50
autodoc_min_relative_importance¶
Minimum Relative Feature Importance Threshold
指定相对特征重要性的最小值,以显示特征。此值必须是大于或等于 0 且小于或等于 1 的浮点数。默认值为 0.003
autodoc_include_permutation_feature_importance¶
Permutation Feature Importance
指定是否计算基于排列的特征重要性。默认会禁用此设置。
autodoc_feature_importance_num_perm¶
Number of Permutations for Feature Importance
指定计算特征重要性时每项特征的排列数。默认值为 1。
autodoc_feature_importance_scorer¶
Feature Importance Scorer
指定计算特征重要性时需使用的评分器名称。将此项设置保留未指定状态,即可为实验使用默认评分器
autodoc_pd_max_rows¶
PDP and Shapley Summary Plot Max Rows
指定在 AutoDoc 中为部分依赖性图 (PDP) 和 Shapley 值摘要图显示的行数。对于超过 autodoc_pd_max_rows 限制的数据集,将进行随机抽样。默认值为 10000。
autodoc_pd_max_runtime¶
PDP Max Runtime in Seconds
指定生成报告时计算部分依赖性需要的最大秒数值。将此数值设置为 -1,即表示无时间限制。
autodoc_out_of_range¶
PDP Out of Range
指定部分依赖性图包含的列范围之外的标准偏差数。这显示了模型会对之前未曾处理过的数据作出何种反应。默认值为 3
autodoc_num_rows¶
ICE Number of Rows
如果未指定单独的行,则指定 PDP 和 ICE 图中的行数。默认值为 0。
autodoc_population_stability_index¶
Population Stability Index
如果实验属于二元分类或回归问题,则指定是否包含群体稳定性指标。默认会禁用此设置。
autodoc_population_stability_index_n_quantiles¶
Population Stability Index Number of Quantiles
指定用于群体稳定性指标的分位点数量。默认值为 10。
autodoc_prediction_stats¶
Prediction Statistics
如果实验属于二元分类或回归问题,则指定是否包含预测统计数据信息。默认会禁用此设置。
autodoc_prediction_stats_n_quantiles¶
Prediction Statistics Number of Quantiles
指定用于预测统计数据的分位点数量。默认值为 20。
autodoc_response_rate¶
Response Rates Plot
如果实验属于二元分类问题,则指定是否包含响应率信息。默认会禁用此设置。
autodoc_response_rate_n_quantiles¶
Response Rates Plot Number of Quantiles
指定用于响应率信息的分位点数量。默认值为 10。
autodoc_gini_plot¶
Show GINI Plot
指定是否显示 GINI 图。默认会禁用此设置。
autodoc_enable_shapley_values¶
Enable Shapley Values
指定是否在 AutoDoc 中显示 Shapley 值结果。默认会启用此设置。
autodoc_global_klime_num_features¶
Global k-LIME Number of Features
指定要在 k-LIME 全局 GLM 系数表中显示的特征数量。此数值必须为大于 0 或 -1 的整数。若需显示所有特征,则将此值设置为 -1。
autodoc_global_klime_num_tables¶
Global k-LIME Number of Tables
指定要在 AutoDoc 中显示的 k-LIME 全局 GLM 系数表的数量。将此数值设置为 1,可显示一个按绝对值排序的系数表。将此数值设置为 2,则可显示两个表格 – 一个为最高正系数表,另一个为最高负系数表。默认值为 1。
autodoc_data_summary_col_num¶
Number of Features in Data Summary Table
指定要在数据摘要表中显示的特征数量。此值必须是整数。若要显示所有列,则指定任何小于 1 的值。默认值为 -1。
autodoc_list_all_config_settings¶
List All Config Settings
指定是否显示所有配置设置。如果禁用此设置,则仅列出已更改的设置。启用时将列出所有设置。默认会禁用此设置。
autodoc_keras_summary_line_length¶
Keras Model Architecture Summary Line Length
指定 Keras 模型架构摘要的行长度。此值必须是大于 0 或 -1 的整数。若要使用默认行长度,则将此值设置为 -1(默认值)。
autodoc_transformer_architecture_max_lines¶
NLP/Image Transformer Architecture Max Lines
指定为“特征”一节中高级转换器架构显示的最大行数。请注意,完整的架构可在附录中找到。
autodoc_full_architecture_in_appendix¶
Appendix NLP/Image Transformer Architecture
指定是否在附录中显示完整的 NLP/图像转换器架构。默认会禁用此设置。
autodoc_coef_table_appendix_results_table¶
Full GLM Coefficients Table in the Appendix
指定是否在附录中显示完整的 GLM 系数表。默认会禁用此设置。
autodoc_coef_table_num_models¶
GLM Coefficient Tables Number of Models
指定在 AutoDoc 中显示了 GLM 系数表的模型数量。此值必须为 -1 或 >= 1 的整数。将此值设置为 -1 即可显示所有模型的系数表。默认值为 1。
autodoc_coef_table_num_folds¶
GLM Coefficient Tables Number of Folds Per Model
指定在 AutoDoc 中显示了 GLM 系数表的每个模型的折叠数。此值必须为 -1(默认值)或 >= 1 的整数(设置为 -1 时,将显示每个模型的所有折叠)。
autodoc_coef_table_num_coef¶
GLM Coefficient Tables Number of Coefficients
指定要在 AutoDoc 内的 GLM 系数表中显示的系数数量。默认值为 50。设置为 -1 时,将显示所有系数。
autodoc_coef_table_num_classes¶
GLM Coefficient Tables Number of Classes
指定要在 AutoDoc 内的 GLM 系数表中显示的类别数量。设置为 -1 时,将显示所有类别。默认值为 9。
autodoc_num_histogram_plots¶
Number of Histograms to Show
指定要显示直方图的主要特征数量。默认值为 10。