Get started with single purpose MTurk APIs¶
Prerequisites:¶
- You have Set up your Amazon Mechanical Turk (MTurk) Requester account and AWS account
- You have Set up permissions to call an MTurk single purpose API
- You have configured a local AWS profile to call MTurk with the user you set up in step 2
- You have prepaid for HITs in your MTurk Requester account to cover paying for Worker rewards (suggested amount to start is $5.00)
If you haven't done so, install the mturk-crowd-beta Python client.¶
!pip install --upgrade mturk-crowd-beta-client --ignore-installed six
Next we will import the packages we need to use an API.¶
You'll need to do this before calling any the APIs.
from mturk_crowd_beta_client import MTurkCrowdClient
from boto3.session import Session
import uuid
Next we set up a session.¶
This examples assume you have a local AWS profile named 'mturk-crowd-caller', but you can authenticate however you like, including by directly passing in your access key and secret key. The access key and secret key are for the User you created during setup with the policies AmazonMechanicalTurkFullAccess and AmazonMechanicalTurkCrowdFullAccess.
session = Session(profile_name='mturk-crowd-caller')
crowd_client = MTurkCrowdClient(session)
Input: { "text": "Everything is wonderful!" }
Result: {'sentiment': 'positive'}
Max length of the input text is 400 characters. Sentiment is one of positive, negative, neutral or cannot determine.
When you create a Task using the sentiment-analysis API, you're automatically creating a Human Intelligence Task (HIT) on worker.mturk.com. Here's an example of a sentiment analysis HIT.
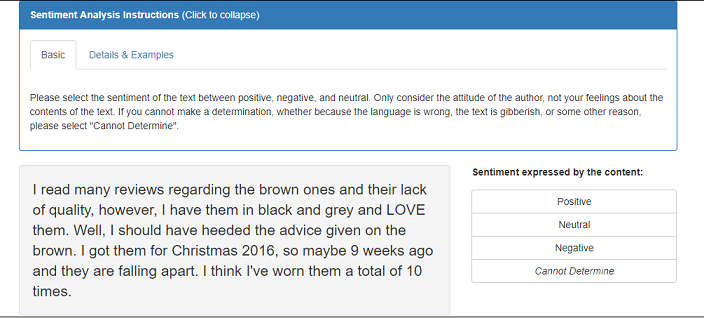
For more information, refer to the sentiment-analysis API documentation.
Create a Task¶
#set the function_name to the name of the API
function_name = 'sentiment-analysis'
# automatically generate a random task ID
task_name = 'my-test-task-' + uuid.uuid4().hex
print(task_name)
# define the text that you want analyzed, up to 400 characters
text = 'The trip by @VP Pence was long planned. He is receiving great praise for leaving game after the players showed such disrespect for country!'
# create a single task with the input you specified above
put_result = crowd_client.put_task(function_name,
task_name,
{'text': text})
print('PUT response: {}'.format(
{'status_code': put_result.status_code, 'task': put_result.json()}))
Get the result¶
Wait a few minutes before calling get_task to give Workers a chance to submit answers.
get_result = crowd_client.get_task(function_name, task_name)
print('GET response: {}'.format(
{'status_code': get_result.status_code, 'task': get_result.json()}))
Creating multiple Tasks and processing results¶
Next, we'll read from a CSV file that has multiple rows of text that needs to be analyzed for sentiment using the pandas library. As a prerequisite you need to have installed the pandas library.
import pandas as pd
#read the input data from csv into a pandas DataFrame
data = pd.read_csv('https://s3-us-west-2.amazonaws.com/mturk-sample-datasets/sentiment-analysis-example-inputs.csv')
# column 1 is the Task ID and column2 is the input data
data
#loop through the rows and create a Task per row, write the put_task status in a new column
status_codes = []
for index, row in data.iterrows():
put_result = crowd_client.put_task(function_name, row.task_id,{'text': row.review_text})
status_codes.append(put_result.status_code)
data['status_codes'] = status_codes
data
We'll call get_task periodically until all of the Tasks reach the "completed" state.
# loop through the rows and get results, store the state and results in new columns
status_codes = []
responses = []
for index, row in data.iterrows():
get_result = crowd_client.get_task(function_name, row.task_id)
status_codes.append(get_result.status_code)
responses.append(get_result.json())
data['status_codes'] = status_codes
data['state'] = [r['state'] for r in responses]
data['problem_details'] = [r['problemDetails'] for r in responses]
if 'processing' in data['state'].unique():
data['sentiment'] = 'data still pending'
else:
data['sentiment'] = [r['result']['sentiment'] for r in responses]
data
Given an image and a type of object to look for, this API returns true or false.
Input: {"image": {"url": "https://www.mturk.com/media/butterbean.jpg"}, "target": {"label": "dog"} }
Result: {"containsTarget": true}
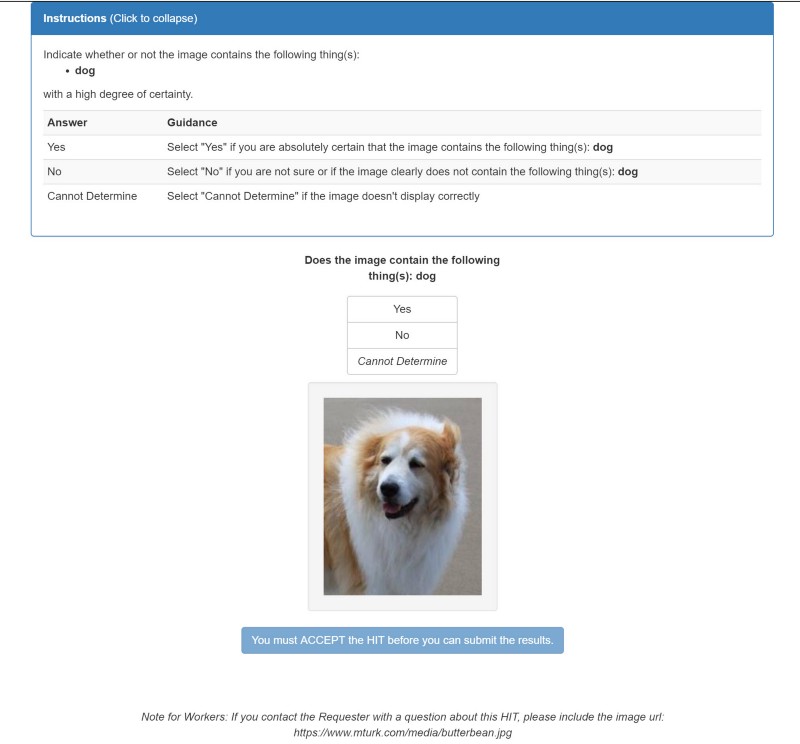
For more information, refer to the image-contains API documentation.
function_name = 'image-contains-test'
Create a Task¶
# automatically generate a random task ID
task_name = 'my-test-task-' + uuid.uuid4().hex
print(task_name)
# the URL of the image that you want annotated
image_url = 'https://urbanedge.blogs.rice.edu/files/2016/02/midtown-15wd4ck.jpg'
The type of thing we're looking for¶
label = 'Pedestrians'
# create a single task with the input you specified above
put_result = crowd_client.put_task(function_name,
task_name,
{'image': {'url': image_url}, 'target': {'label': label}})
print('PUT response: {}'.format(
{'status_code': put_result.status_code, 'task': put_result.json()}))
Get the result¶
Wait a few minutes before calling get_task to give Workers a chance to submit answers.
get_result = crowd_client.get_task(function_name, task_name)
print('GET response: {}'.format(
{'status_code': get_result.status_code, 'task': get_result.json()}))
Creating multiple Tasks and processing results¶
Next, we'll read from a CSV file that has multiple rows of text that needs to be analyzed for sentiment using the pandas library. As a prerequisite you need to have installed the pandas library.
import pandas as pd
#read the input data from csv into a pandas DataFrame
data = pd.read_csv('https://s3-us-west-2.amazonaws.com/mturk-sample-datasets/image-contains-example-inputs.csv')
# column 1 is the Task ID and column2 amd 3 are the input data
data
#loop through the rows and create a Task per row, write the put_task status in a new column
status_codes = []
for index, row in data.iterrows():
put_result = crowd_client.put_task(function_name,
row.task_id,
{'image': {'url': row.image_url},
'target': {'label': row.Label} })
status_codes.append(put_result.status_code)
data['status_codes'] = status_codes
data
We'll call get_task periodically until all of the Tasks reach the "completed" state.
# loop through the rows and get results, store the state and results in new columns
status_codes = []
responses = []
for index, row in data.iterrows():
get_result = crowd_client.get_task(function_name, row.task_id)
status_codes.append(get_result.status_code)
responses.append(get_result.json())
data['status_codes'] = status_codes
data['state'] = [r['state'] for r in responses]
data['problem_details'] = [r['problemDetails'] for r in responses]
if 'processing' in data['state'].unique():
data['containsTarget'] = 'data still pending'
else:
data['containsTarget'] = [r['result']['containsTarget'] for r in responses]
data
data.to_csv('image-contains-results.csv')
emotion-detection¶
This API determines the emotion of text.
Input:{"text": "First time ever winning all three fantasy leagues AND @Seahawks win!"}
Result: {"emotion": "joy"}
Emotion is one of Joy, Anger, Fear, Sadness, Surprise, Disgust, or Neutral.
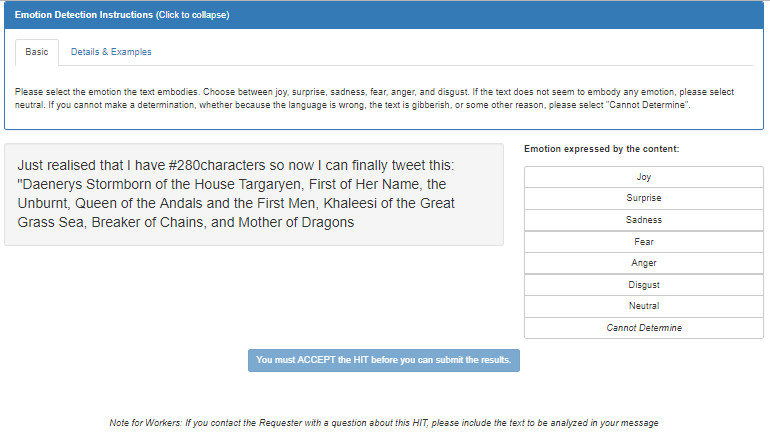
For more information, refer to the emotion-detection API documentation.
function_name = 'emotion-detection'
Create a Task¶
# automatically generate a random task ID
task_name = 'my-test-task-' + uuid.uuid4().hex
print(task_name)
# define the text that you want analyzed, up to 16k
text = 'Just realised that I have #280characters so now I can finally tweet this: "Daenerys Stormborn of the House Targaryen, First of Her Name, the Unburnt, Queen of the Andals and the First Men, Khaleesi of the Great Grass Sea, Breaker of Chains, and Mother of Dragons'
# create a single task with the input you specified above
put_result = crowd_client.put_task(function_name,
task_name,
{'text': text})
print('PUT response: {}'.format(
{'status_code': put_result.status_code, 'task': put_result.json()}))
Get the result¶
Wait a few minutes before calling get_task to give Workers a chance to submit answers.
get_result = crowd_client.get_task(function_name, task_name)
print('GET response: {}'.format(
{'status_code': get_result.status_code, 'task': get_result.json()}))
semantic-similarity
Compare two text documents and rate them on how similar they are, on a scale between 0 and 1 where 1 is very similar.
Input: {"text1": "The sky is blue.", "text2": "The sky was the color of blue."}
Result: {"similarityScore": 0.75}
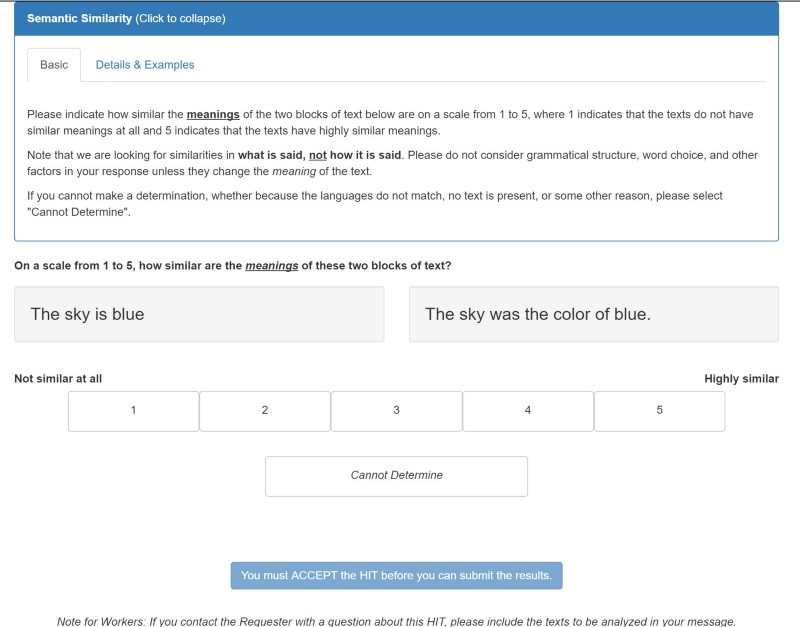
For more information, refer to the semantic-similarity API documentation.
function_name = 'semantic-similarity'
Create a Task¶
# automatically generate a random task ID
task_name = 'my-test-task-' + uuid.uuid4().hex
print(task_name)
# define the text that you want analyzed, up to 16k
text1 = 'I\'m so hungry I could eat a horse'
text2 = 'I\'m hangry'
#create a single task with the input you specified above
put_result = crowd_client.put_task(function_name,
task_name,
{'text1': text1, 'text2': text2})
print('PUT response: {}'.format(
{'status_code': put_result.status_code, 'task': put_result.json()}))
Get the result¶
Wait a few minutes before calling get_task to give Workers a chance to submit answers.
get_result = crowd_client.get_task(function_name, task_name)
print('GET response: {}'.format(
{'status_code': get_result.status_code, 'task': get_result.json()}))
Creating multiple Tasks and processing results¶
Next, we'll read from a CSV file that has multiple rows of text that needs to be analyzed for sentiment using the pandas library. As a prerequisite you need to have installed the pandas library.
import pandas as pd
#read the input data from csv into a pandas DataFrame
data = pd.read_csv('https://s3-us-west-2.amazonaws.com/mturk-sample-datasets/semantic-similarity-example-inputs.csv')
# column 1 is the Task ID and column2 is the input data
data
#loop through the rows and create a Task per row, write the put_task status in a new column
status_codes = []
for index, row in data.iterrows():
put_result = crowd_client.put_task(function_name,
row.task_id,
{'text1': row.review1, 'text2': row.review2})
status_codes.append(put_result.status_code)
data['status_codes'] = status_codes
data
We'll call get_task periodically until all of the Tasks reach the "completed" state.
# loop through the rows and get results, store the state and results in new columns
status_codes = []
responses = []
for index, row in data.iterrows():
get_result = crowd_client.get_task(function_name, row.task_id)
status_codes.append(get_result.status_code)
responses.append(get_result.json())
data['status_codes'] = status_codes
data['state'] = [r['state'] for r in responses]
data['problem_details'] = [r['problemDetails'] for r in responses]
if 'processing' in data['state'].unique():
data['result'] = [r['result'] for r in responses]
else:
data['similarityScore'] = [r['result']['similarityScore'] for r in responses]
data
image-categorization¶
Given an image URL and a list of categories, determine which category the image best belongs to. You can optionally provide a description for each category to provide more guidance on what each category includes.
Input:
{
"input": {
"image":{"url": "https://s3-us-west-2.amazonaws.com/...1m.png"},
"categories": [
{'label': 'Ankle Boot',
'description': 'description1' ,
'positiveExamples': [
{'image': {'url':'https://s3-...1d.jpg'}}
] ,
'negativeExamples': [
{'image': {'url':'https://s3-...1i.jpg'}}
]
},
{'label': 'Wedge',
'description': 'description2 ',
'positiveExamples': [
{'image': {'url':'https://s3-...1l.png'}}
] ,
'negativeExamples': [
{'image': {'url':'https://s3-...1i.png'}}
]
},
]
}
}Result: {"matches": [{"label":"Wedge"}]}
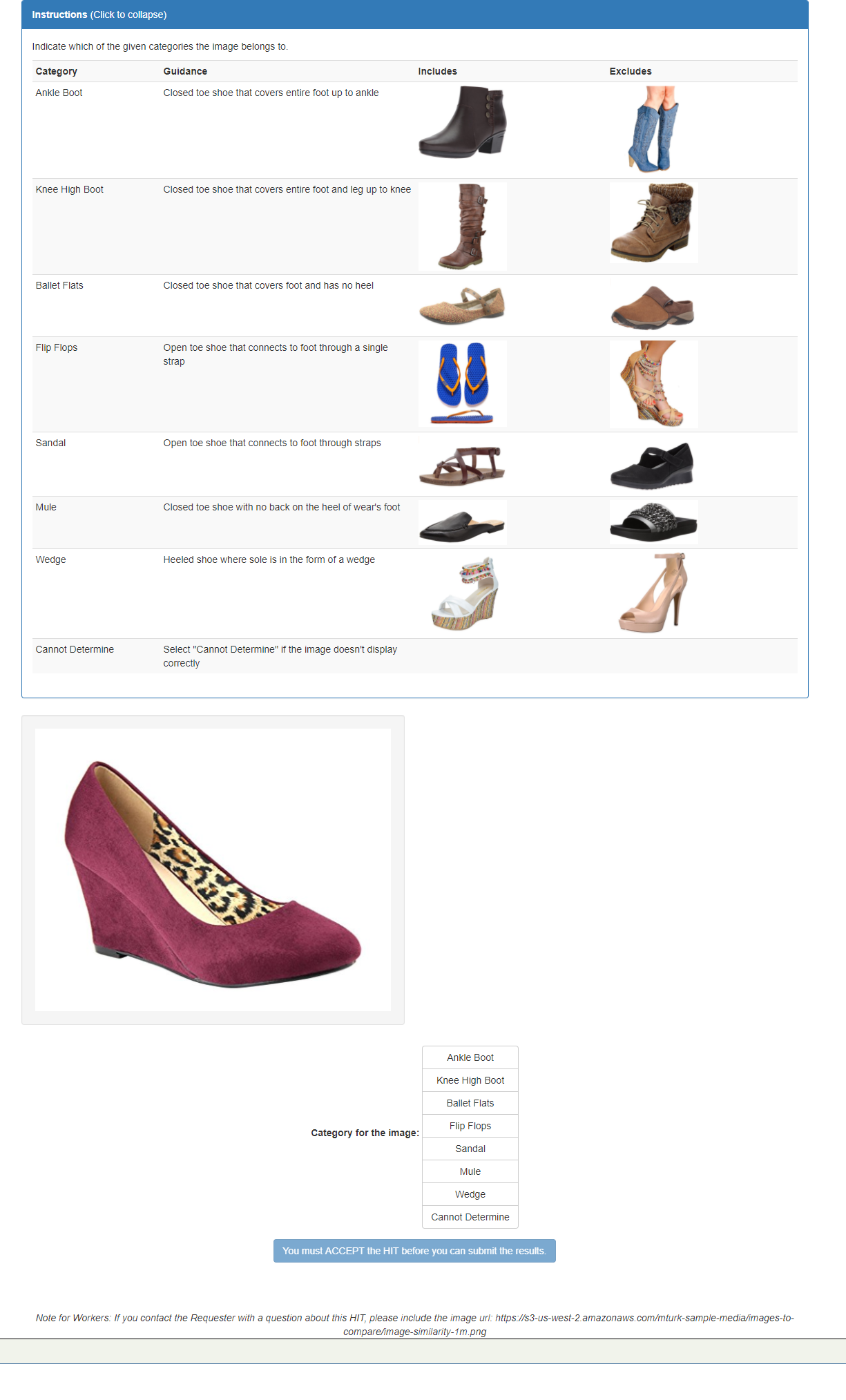
For more information, refer to the image-categorization API documentation.
function_name = 'image-categorization'
Create a Task¶
# automatically generate a random task ID
task_name = 'my-test-task-' + uuid.uuid4().hex
print(task_name)
# provide the context and the intent
image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1m.png'
label1 = 'Ankle Boot'
label2 = 'Knee High Boot'
label3 = 'Ballet Flats'
label4 = 'Flip Flops'
label5 = 'Sandal'
label6 = 'Mule'
label7 = 'Wedge'
# Descriptions amd example images are optional, but help guide the worker.
description1 = 'Closed toe shoe that covers entire foot up to ankle'
description2 = 'Closed toe shoe that covers entire foot and leg up to knee'
description3 = 'Closed toe shoe that covers foot and has no heel'
description4 = 'Open toe shoe that connects to foot through a single strap'
description5 = 'Open toe shoe that connects to foot through straps'
description6 = 'Closed toe shoe with no back on the heel of wear\'s foot'
description7 = 'Heeled shoe where sole is in the form of a wedge'
example1_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1d.jpg'
example2_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1z.jpg'
example3_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1dd.png'
example4_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1b.png'
example5_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1r.png'
example6_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1x.png'
example7_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1l.png'
example1b_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1i.jpg'
example2b_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1f.jpg'
example3b_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1y.png'
example4b_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1l.jpg'
example5b_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1q.jpg'
example6b_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1t.png'
example7b_image_url = 'https://s3-us-west-2.amazonaws.com/mturk-sample-media/images-to-compare/image-similarity-1i.png'
# Create the task
put_result = crowd_client.put_task(function_name,
task_name,
{'image': {'url': image_url},
'categories': [ {'label': label1, 'description': description1 ,
'positiveExamples': [{'image': {'url': example1_image_url}}] ,
'negativeExamples': [{'image': {'url': example1b_image_url}}] },
{'label': label2, 'description': description2,
'positiveExamples': [{'image': {'url': example2_image_url}}] ,
'negativeExamples': [{'image': {'url': example2b_image_url}}] },
{'label': label3, 'description': description3,
'positiveExamples': [{'image': {'url': example3_image_url}}] ,
'negativeExamples': [{'image': {'url': example3b_image_url}}] },
{'label': label4, 'description': description4,
'positiveExamples': [{'image': {'url': example4_image_url}}] ,
'negativeExamples': [{'image': {'url': example4b_image_url}}] },
{'label': label5, 'description': description5,
'positiveExamples': [{'image': {'url': example5_image_url}}] ,
'negativeExamples': [{'image': {'url': example5b_image_url}}] },
{'label': label6, 'description': description6,
'positiveExamples': [{'image': {'url': example6_image_url}}] ,
'negativeExamples': [{'image': {'url': example6b_image_url}}] },
{'label': label7, 'description': description7,
'positiveExamples': [{'image': {'url': example7_image_url}}] ,
'negativeExamples': [{'image': {'url': example7b_image_url}}] }] })
print('PUT response: {}'.format(
{'status_code': put_result.status_code, 'task': put_result.json()}))
Get the result¶
Wait a few minutes before calling get_task to give Workers a chance to submit answers.
get_result = crowd_client.get_task(function_name, task_name)
print('GET response: {}'.format(
{'status_code': get_result.status_code, 'task': get_result.json()}))
Given a list of intentions, categorize the best intention that matches the text given.
input:
{
"input": {
"text": "my son was stung by bees and I need to know if I need to go to the ER",
"intents":[
{"label": "Schedule an appointment",
"description": "Caller expresses an intent to visit with health care professional"
"positiveExamples": [
{"text": "I need to make an appointment with Dr. Smith" },
{"text": "Can the doctor see me today?"}],
"negativeExamples": [
{"text": "Do you sell burritos?" },
{"text": "Do you accept credit cards?"}] },
{"label": "Medical Record Request",
"description": "Caller expresses a desire to obtain copies of their medical history"
"positiveExamples": [
{"text": "I need a copy of my kids’ immunization records" },
{"text": "Can you fax my test results to my surgeon"}],
"negativeExamples": [
{"text": "I need to refill my prescription"},
{"text": "Do you have my test results?"}] }]
}
}result:{"matches": [{"label": "Schedule an appointment"}]}
Here's an example of what the task might look like for Workers.
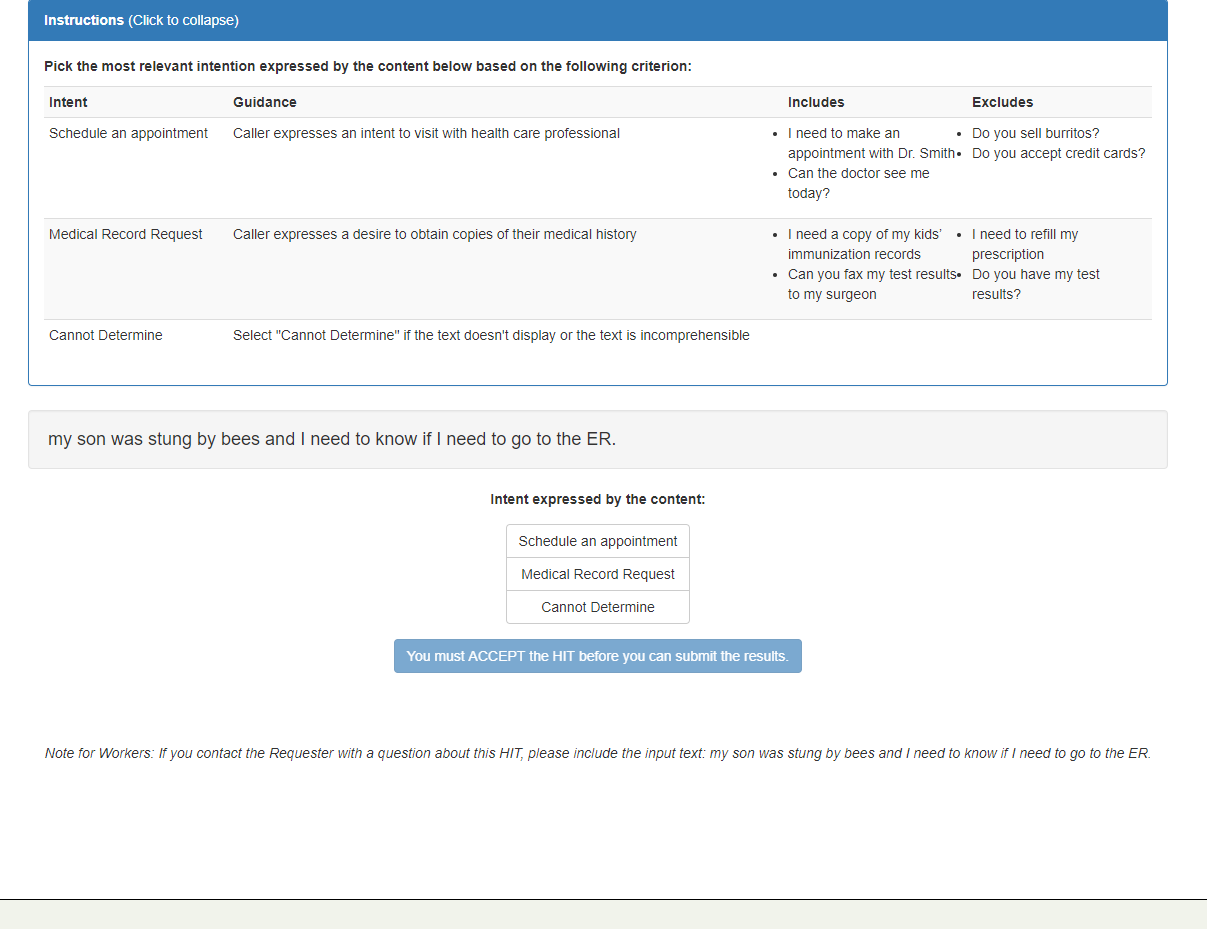
For more information, refer to the intent-detection API documentation.
function_name = 'intent-detection'
Create a Task¶
# automatically generate a random task ID
task_name = 'my-test-task-' + uuid.uuid4().hex
print(task_name)
# define the text to be analysed and a list of intentions to categorize the text for
text = 'my son was stung by bees and I need to know if I need to go to the ER'
intents = [{'label': 'Schedule an appointment', 'description': 'e.g. I need to make an appointment with Dr. Smith'}, {'label': 'Medical Record Request', 'description': 'e.g. I need a copy of my kids immunization records'}]
# create a single task with the input you specified above
put_result = crowd_client.put_task(function_name,
task_name,
{'text': text,
'intents': intents})
print('PUT response: {}'.format(
{'status_code': put_result.status_code, 'task': put_result.json()}))
Get the result¶
Wait a few minutes before calling get_task to give Workers a chance to submit answers.
get_result = crowd_client.get_task(function_name, task_name)
print('GET response: {}'.format(
{'status_code': get_result.status_code, 'task': get_result.json()}))
text-categorization
Given a piece of text and a list of categories, choose the best cateogry that fits the text.
input:
{
"input": {
"text": "These are great. They do run a touch small.
I almost could go a half size up from my normal size." ,
"description": "Customer mentions appearance or style of item.',
"categories": [
{"label": "Style",
"description": "Customer mentions appearance or
style of item." ,
"positiveExamples": [
{"text": "Not the color I ordered"},
{"text": "No longer in season"}
] ,
"negativeExamples": [
{"text": "Too large"},
{"text": "Fabric was too thin"}
]
},
{"label": "Fit",
"description": "Customer mentions the cut or
fit of item." ,
"positiveExamples": [
{"text": "This was too short."},
{"text": "Doesn't work for my body type."}
] ,
"negativeExamples": [
{"text": "I don't like the baggy look"},
{"text": "Neckline is too low cut"}
]
}
]
}
}result: {"matches": [{"label" : "Fit"}] }
Here's an example of a HIT to MTurk Workers generated by calling this API.
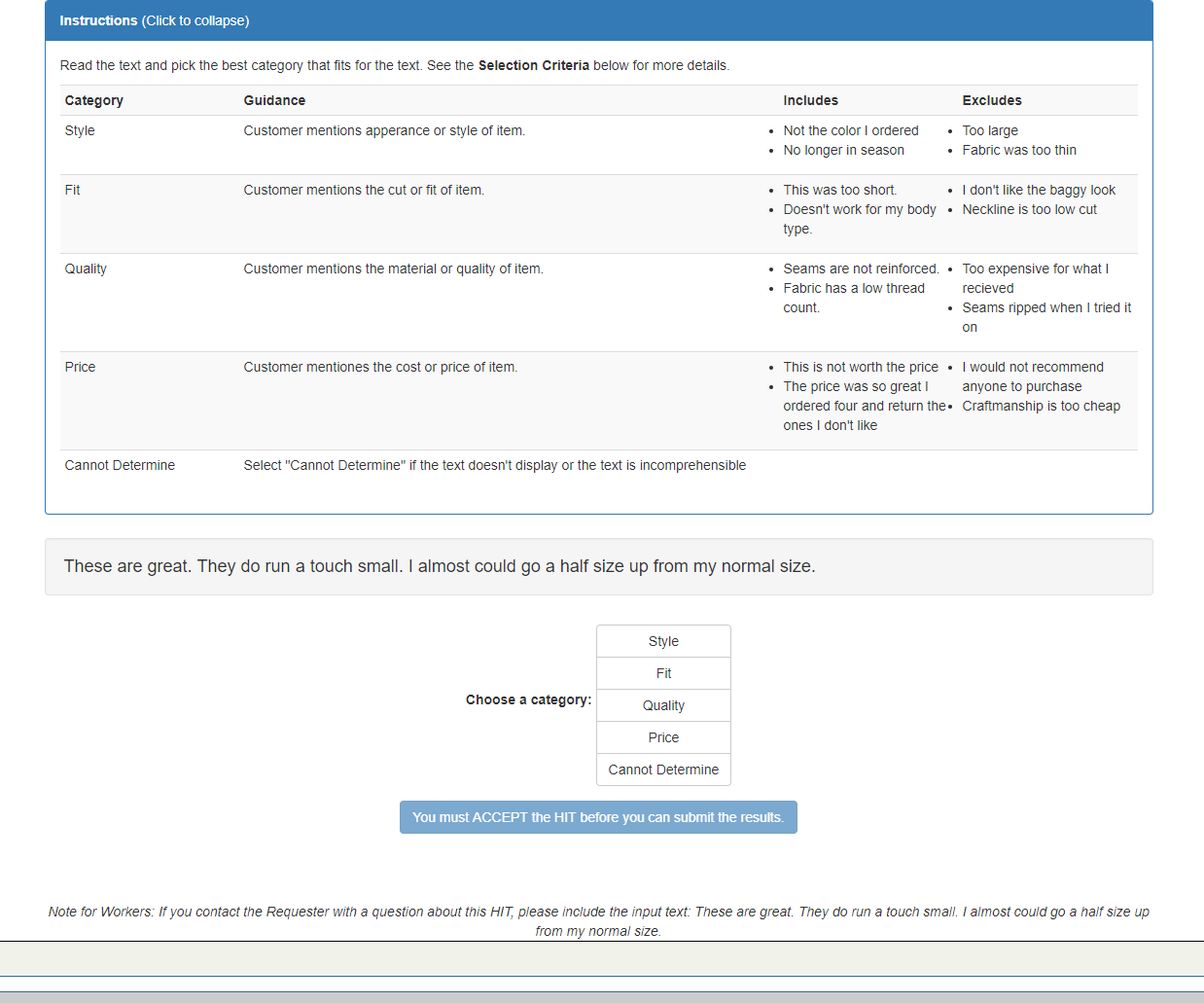
For more information, refer to the text-categorization API documentation.
function_name = 'text-categorization'
Create a Task¶
# automatically generate a random task ID
task_name = 'my-test-task-' + uuid.uuid4().hex
print(task_name)
# define the text to be analysed and a list of categories to assess for
text = 'These are great. They do run a touch small. I almost could go a half size up from my normal size.'
categories = [{'label': 'style', 'description': 'related to the look of the product'}, {'label': 'fit', 'description': 'related to the sizing or how it fits'}, {'label': 'quality', 'description': 'related to how well made the product is'}, {'label': 'price', 'description': 'related to cost or value of the product'}]
# create a single task with the input you specified above
put_result = crowd_client.put_task(function_name,
task_name,
{'text': text,
'categories': categories})
print('PUT response: {}'.format(
{'status_code': put_result.status_code, 'task': put_result.json()}))
Get the result¶
Wait a few minutes before calling get_task to give Workers a chance to submit answers.
get_result = crowd_client.get_task(function_name, task_name)
print('GET response: {}'.format(
{'status_code': get_result.status_code, 'task': get_result.json()}))
image-similarity
This API takes in two images, specified by URL, and returns a score for how similar those two images are.
input: {'input': {'image1': {'url': 'https://requester.mturk.com/assets/lucy.jpg'}, 'image2': {'url': 'https://requester.mturk.com/assets/gold-finding-puppy.jpg'}}
result: {'similarityScore': 0.75}
Here's an example of a HIT that's shown to Workers:
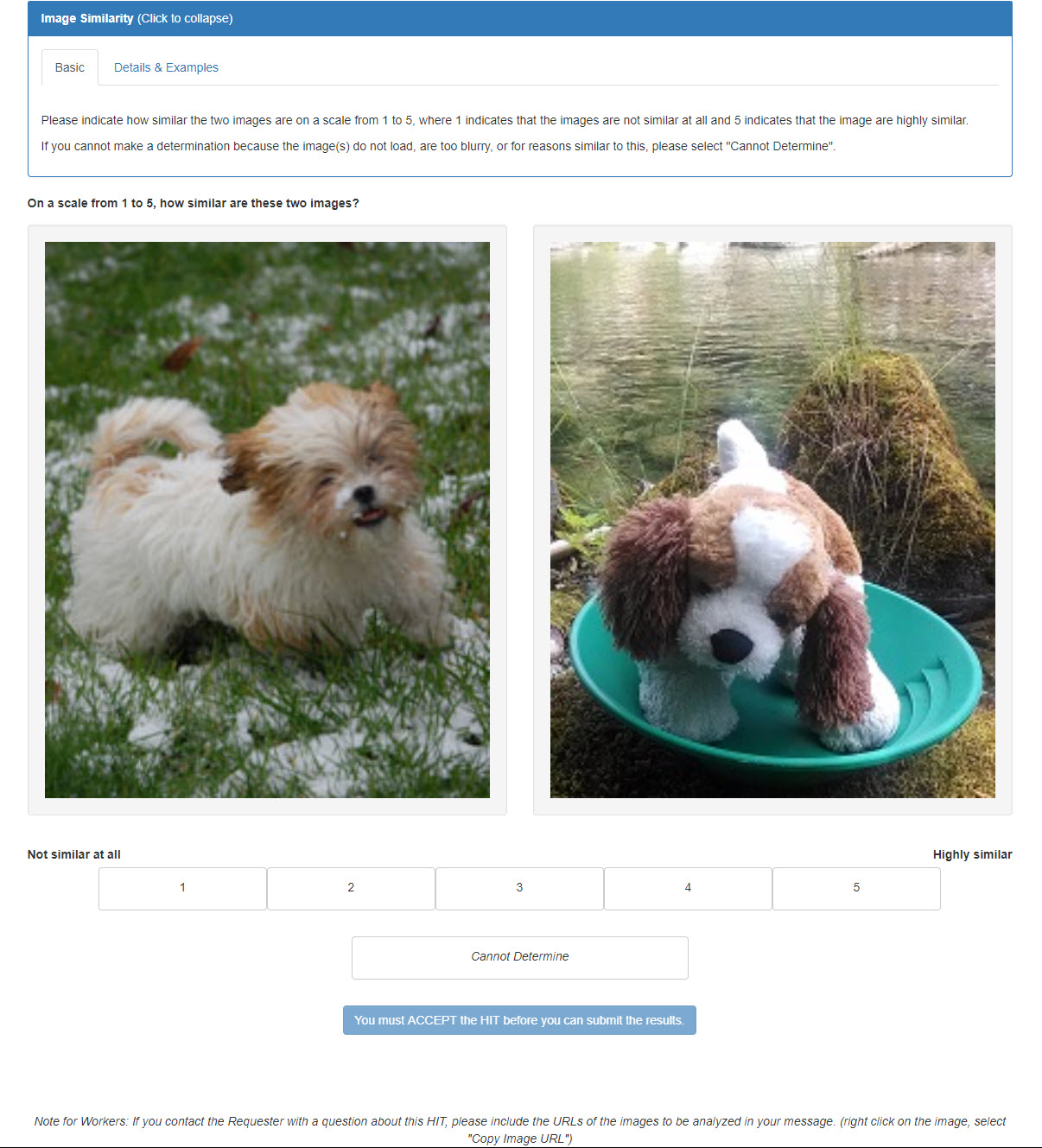
For more information, refer to the image-similarity API documentation.
function_name = 'image-similarity'
Create a Task¶
# automatically generate a random task ID
task_name = 'my-test-task-' + uuid.uuid4().hex
print(task_name)
# the URLs of the images that you want to compare
image_url_1 = 'https://requester.mturk.com/assets/lucy.jpg'
image_url_2 = 'https://requester.mturk.com/assets/gold-finding-puppy.jpg'
# create a single task with the input you specified above
put_result = crowd_client.put_task(function_name,task_name,
{'image1': {'url': image_url_1},
'image2': {'url': image_url_2}})
print('PUT response: {}'.format(
{'status_code': put_result.status_code, 'task': put_result.json()}))
Get the result¶
Wait a few minutes before calling get_task to give Workers a chance to submit answers.
get_result = crowd_client.get_task(function_name, task_name)
print('GET response: {}'.format(
{'status_code': get_result.status_code, 'task': get_result.json()}))