
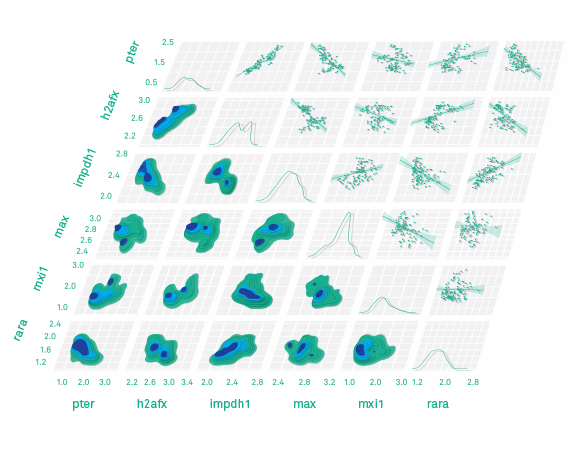
Correlations between expression levels for genes obtained from assays of human tissues under different conditions are shown in this figure, derived in a network visualization work flow. This kind of visualization is used to compare experimental expression levels for transcription factors with expression levels for genes they may regulate directly or indirectly. Here, the visualization focuses on the expression level for the 'pter' gene, shown in the lower left column and upper left row, compared with the expression levels for transcription factors such as h2afx, max, rara and others.
At its essence, computation is applied mathematics boiled down to its core elements: ones, zeroes, and some Boolean logic to connect them. But within those narrow confines lies a profound power to accelerate discovery-driven science. The mission of the Simons Center for Data Analysis (SCDA) is to apply this computational power to the deluge of complex experimental data generated by new techniques in bioinformatics and experimental biology. Storing, transmitting and meaningfully analyzing this so-called 'big data' is an emerging research discipline in its own right. In this regard, the computing and software development groups at SCDA are connected to the long line of technologist-scientists whose methodological discoveries — from Robert Hooke's compound microscope in the 17th century to Cooley and Tukey's fast Fourier transform or Greengard and Rokhlin's fast multipole method in the 20th — have both supported and inspired the search for knowledge. "Our job," says Ian Fisk, SCDA's deputy director for computing, "is to make sure that computers are not the limiting factor in terms of scientific progress."
In the past year, SCDA has dramatically expanded its software and computing capabilities. What began in 2014 as a single server running without its own machine room has grown into a high-performance computing network. SCDA can now apply the power of 700 processing cores (about 300 times as many as the average laptop), nearly a petabyte of high-performance storage (enough to store almost one-fifth of the Library of Congress's digital materials), and a 10-gigabit network infrastructure (fast enough to transfer a 200-gigabyte fully sequenced human genome in less than three minutes) to solving the problems of discovery-driven science. A single specialized node in SCDA's computing cluster has 48 processing cores and 1.5 terabytes of RAM, allowing researchers to quickly find correlations within the extremely large datasets that genomics and neuroscience routinely generate. "It's a lot of power in one box," Fisk says.
The computing and software development groups work directly with SCDA's genomics, neuroscience and systems biology teams as scientific and algorithmic collaborators, not just tool builders. "I certainly consider myself a researcher, and our people are embedded in the science programs here," says Nick Carriero, who leads SCDA's software development group. "A colleague might wander into one of our offices, trying to understand something experimentally, but they don't know quite how to set up the correct in silico apparatus to do it. They're not experts in computation. We meet with them and understand the nature of their problem. That's an important part of having an operation structured like SCDA, which is small, intimate, with a lot of give and take between all parties."
But if computing supports the math at SCDA, the math in turn enables the computing. The center's genomics, neuroscience and systems biology research groups routinely access and manipulate enormously large and complex files, which must be constantly verified to ensure that no data has become accidentally corrupted. SCDA uses a mathematical function known as 'MD5 checksum' to continuously validate the integrity of its files. The MD5 algorithm applies a calculation to each file that converts it into a unique integer (the checksum). This number acts as the file's mathematical 'fingerprint' any time the data are copied or transmitted. Any unintended change in the data will cause the MD5 function to calculate a drastically different value for the checksum, which makes damaged files easy to spot.
SCDA runs this calculation continuously to safeguard against the unavoidable breakdowns that afflict high-performance computing systems. "Once you start working with data at scale, this becomes a problem that you can't ignore," explains Carriero. "It would be an unusual event for the hard drive in an ordinary laptop to fail. But for us, that's a normal event. We exploit this mathematical capability so that we can do the necessary verification of all our data."
Complex real-time analysis is also the purpose of SCDA's 21-million-pixel video wall, which allows researchers to examine ultra-high-definition visualizations of their data. Unlike pixels in commercial video walls, those in SCDA's screen are individually controlled by four graphics processing units that power the display. This means that resolution — rather than mere magnification — is enhanced in a way that supports detailed visual investigation of complex systems such as protein simulations or genetic regulatory networks.
"These structures can be extremely complicated with hundreds or thousands of features that are essentially impossible to visually resolve on a normal computer monitor," Carriero says. "This highly immersive visualization lets a researcher ask a dynamic series of 'what if' questions about the data: What happens to the network if I remove this gene? What if I switch from thinking about lung to liver tissue? What if I constrain myself to one group of species as opposed to another?" Still, as Fisk says, "The most interesting math comes in preparing what goes on the wall" — that is, doing the science itself.
Fisk's and Carriero's groups have also been collaborating with SFARI to make genomic data from hundreds (and eventually thousands) of families in the Simons Simplex Collection accessible to autism investigators. The primary hurdle in using this unique collection of data is its sheer size. Each sequenced genome contains approximately 200 gigabytes of information, and analyzing multiple genomes in a cohort can often require unwieldy file transfers. "Some of these files are individually about the size of half of the disk drive inside of your laptop," says Carriero. "A family of four is close to a terabyte of data, and if you have 1,000 families, that's a petabyte of data."
Luckily, most autism investigators aren't interested in comparing whole genomes but rather differences between two or more discrete sequences. Yet generating even this relatively small volume of variant data requires substantial computation over large amounts of input and — again — more computing and storage hardware. Although transmission of only genetic variants may reduce gargantuan file sizes, because several algorithmic procedures for computing these genetic variations are in use in the field, and because each impacts results differently, researchers may need to perform their own analysis with the full raw dataset anyway.
The arithmetic around adding more storage may be simple, but putting the new systems in place is not. "It's not too hard to call up somebody like Dell, Hewlett-Packard or IBM and order a rack's worth of computing equipment," says Carriero, "but it's surprisingly hard to get a petabyte of storage that's going to be high-performance and reliable enough for scientific computing at scale."
