Google BigQuery 설정¶
Driverless AI를 사용하면 Driverless AI 애플리케이션 내에서 Google BigQuery (GBQ) 데이터 소스의 탐색이 가능합니다. 해당 섹션에서는 GBQ에서 작동할 수 있도록 Driverless AI의 구성 방법에 관해 설명합니다. 본 설정을 사용하려면 인증을 활성화해야 합니다. GCS 및/또는 GBQ 커넥터의 활성화를 통해 해당 파일 시스템을 UI에서 사용할 수 있지만 인증 없이는 해당 커넥터를 사용할 수 없습니다.
인증해서 GBQ 데이터 커넥터를 사용하려면 다음을 수행하십시오.
GCP에서 JSON 인증 파일을 검색하십시오.
Docker 인스턴스에 JSON 파일을 마운트하십시오.
gcs_path_to_service_account_json config 옵션을 통해 /json_auth_file.json의 경로를 지정하십시오.
Notes:
계정 JSON은 시스템 관리자가 제공한 인증을 포함합니다. Google Cloud Storage와 Google BigQuery 인증을 모두 포함하는 JSON 파일을 제공받을 수 있고, 둘 중 하나만 포함하거나 아무것도 포함하지 않을 수 있습니다.
Docker 설치 버전에 따라, Driverless AI Docker 이미지를 시작할 때는
docker run --runtime=nvidia(Docker 19.03 이후) 또는nvidia-docker(Docker 19.03 이전) 명령을 사용하십시오. 사용 중인 Docker 버전을 확인하려면docker version을 사용하십시오.
다음 섹션에서는 GBQ 데이터 커넥터를 활성화하는 방법을 설명합니다.
config.toml 파일로 GBQ 활성화¶
본 예제에서는 JSON 인증 파일을 패스하여 인증을 통해 GBQ 데이터 커넥터를 활성화합니다. 여기서는 JSON 파일에 Google BigQuery 인증이 포함되어 있다고 가정합니다.
nvidia-docker run \
--pid=host \
--rm \
--shm-size=256m \
-e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,gbq" \
-e DRIVERLESS_AI_GCS_PATH_TO_SERVICE_ACCOUNT_JSON="/service_account_json.json" \
-u `id -u`:`id -g` \
-p 12345:12345 \
-v `pwd`/data:/data \
-v `pwd`/log:/log \
-v `pwd`/license:/license \
-v `pwd`/tmp:/tmp \
-v `pwd`/service_account_json.json:/service_account_json.json \
h2oai/dai-centos7-x86_64:1.10.2-cuda11.2.2.xx
이 예제에서는 config.toml 파일에서 GBQ 데이터 커넥터 옵션을 구성하는 방법과 Docker에서 Driverless AI의 시작 시 해당 파일을 지정하는 방법을 보여줍니다.
Driverless AI config.toml file 파일을 구성하십시오. 다음 구성 옵션을 설정하십시오:
enabled_file_systems = "file, upload, gbq"
gcs_path_to_service_account_json = "/service_account_json.json"
config.toml 파일을 Docker 컨테이너에 마운트하십시오.
nvidia-docker run \ --pid=host \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:1.10.2-cuda11.2.2.xx
본 예제에서는 JSON 인증 파일을 패스하여 인증을 통해 GBQ 데이터 커넥터를 활성화합니다. 여기서는 JSON 파일에 Google BigQuery 인증이 포함되어 있다고 가정합니다.
Driverless AI config.toml 파일을 내보내거나 ~/.bashrc에 추가합니다. 아래 예를 참조하십시오.
# DEB and RPM export DRIVERLESS_AI_CONFIG_FILE="/etc/dai/config.toml" # TAR SH export DRIVERLESS_AI_CONFIG_FILE="/path/to/your/unpacked/dai/directory/config.toml"
config.toml 파일에서 아래 구성 옵션을 지정하십시오.
# File System Support # file : local file system/server file system # gbq : Google Big Query, remember to configure gcs_path_to_service_account_json below enabled_file_systems = "file, gbq" # GCS Connector credentials # example (suggested) -- "/licenses/my_service_account_json.json" gcs_path_to_service_account_json = "/service_account_json.json"
완료되면 변경 사항을 저장하고 Driverless AI를 중지/재시작하십시오.
환경 변수를 설정하여 GBQ 활성화¶
GBQ 데이터 커넥터는 GOOGLE_APPLICATION_CREDENTIALS 환경 변수를 다음과 같이 설정하여 구성할 수 있습니다.
export GOOGLE_APPLICATION_CREDENTIALS="SERVICE_ACCOUNT_KEY_PATH"
앞의 예에서 SERVICE_ACCOUNT_KEY_PATH 를 사용자의 서비스 계정 키가 포함된 JSON 파일의 경로로 바꿉니다. 다음은 이것이 어떻게 보이는지 보여주는 예입니다.
export GOOGLE_APPLICATION_CREDENTIALS="/etc/dai/service-account.json"
Docker를 사용하여 이 환경 변수를 설정하는 방법을 보려면 다음 예를 참조하십시오.
nvidia-docker run \
--pid=host \
--rm \
--shm-size=256m \
-e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,gbq" \
-e GOOGLE_APPLICATION_CREDENTIALS="/service_account.json" \
-u `id -u`:`id -g` \
-p 12345:12345 \
-v `pwd`/data:/data \
-v `pwd`/log:/log \
-v `pwd`/license:/license \
-v `pwd`/tmp:/tmp \
-v `pwd`/service_account_json.json:/service_account_json.json \
h2oai/dai-centos7-x86_64:1.10.2-cuda11.2.2.xx
GOOGLE_APPLICATION_CREDENTIALS 환경 변수 설정에 대한 자세한 내용은 환경 변수 설정에 대한 공식 문서 를 참조하십시오.
GKE 클러스터에 대해 워크로드 아이덴티티를 활성화하여 GBQ 활성화¶
GBQ 데이터 커넥터는 Google Kubernetes Engine(GKE) 클러스터에 대한 워크로드 아이덴티티를 활성화하여 구성할 수 있습니다. 워크로드 아이덴티티를 활성화하는 방법에 대해서는 GKE 클러스터에서 워크로드 아이덴티티 활성화에 대한 공식 문서 를 참조하십시오.
참고
워크로드 아이덴티티가 활성화된 경우 GOOGLE_APPLICATION_CREDENTIALS 환경 변수를 설정할 필요가 없습니다.
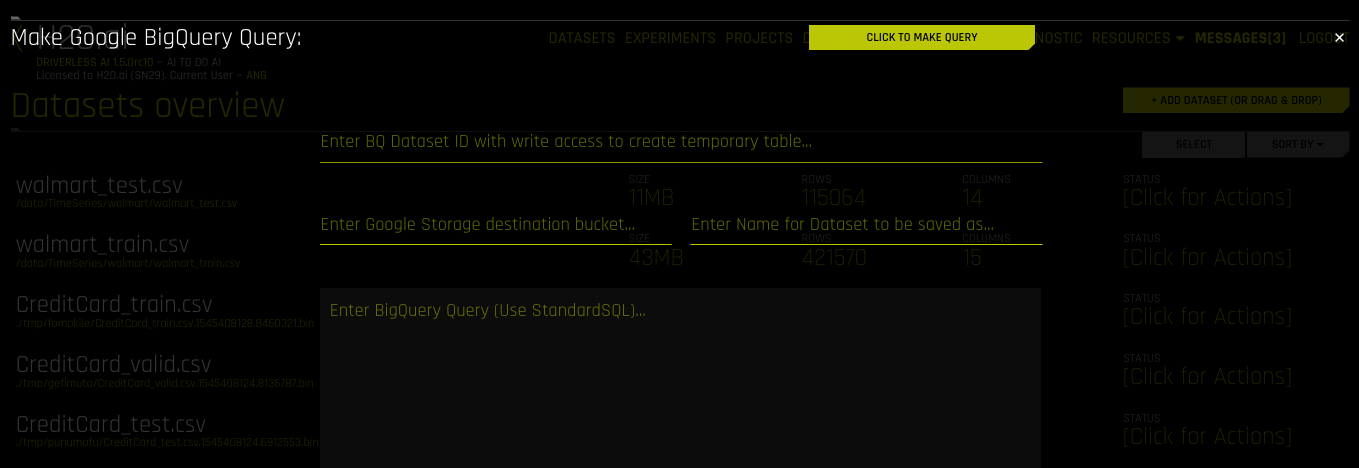
GBQ를 사용하여 데이터 세트 추가¶
Google BigQuery가 활성화된 후, Add Dataset (or Drag and Drop) 드롭다운 메뉴에서 Google Big Query 를 선택하여 데이터 세트를 추가할 수 있습니다.

데이터 세트를 추가하려면 다음 정보를 지정하십시오.
Enter BQ Dataset ID with write access to create temporary table: 이 사용자가 읽기/쓰기 액세스 권한을 가진 Google BigQuery에 데이터 세트 ID를 입력합니다. BigQuery는 해당 데이터 세트를 쿼리에 의해 생성된 새 테이블의 위치로 사용합니다.
Note: GBQ에 대한 Driverless AI의 연결은 서비스 JSON 파일에서 최상위 디렉터리를 상속합니다. 따라서 《my-dataset》 라고 불리는 데이터 세트가 《dai-gbq》 라고 불리는 최상위 디렉터리에 위치한 경우, 데이터 세트 ID 입력 필드의 값은 《dai-gbq:my-dataset》 가 아니라 《my-dataset》 입니다.
Enter Google Storage destination bucket: Google Cloud Storage 대상 버킷의 이름을 지정합니다. 해당 사용자는 이 버킷에 대한 쓰기 액세스 권한을 갖고 있어야 합니다.
Enter Name for Dataset to be saved as : 데이터 세트의 이름(예:
my_file) 을 지정합니다.Enter BigQuery Query (Use StandardSQL): BigQuery에서 실행하고자 하는 StandardSQL 쿼리를 입력합니다. 예:
SELECT * FROM <my_dataset>.<my_table>.(선택) GBQ 커넥터와 함께 사용할 프로젝트를 지정합니다. 이는 명령줄 인터페이스 사용 시
--project를 제공하는 것과 같습니다.완료하면 Click to Make Query 버튼을 선택하여 데이터 세트를 추가하십시오.